ShardingStage3_Zero3
paddle中model和opt的处理放在同一个ShardingStage3类
grad的分片,是指param.grad分片,而每一层输入输出的grad由自动微分框架保存,是不做分片的
当前paddle中的实现以模型曾为单位逐层推进,每次仅处理一层的参数。
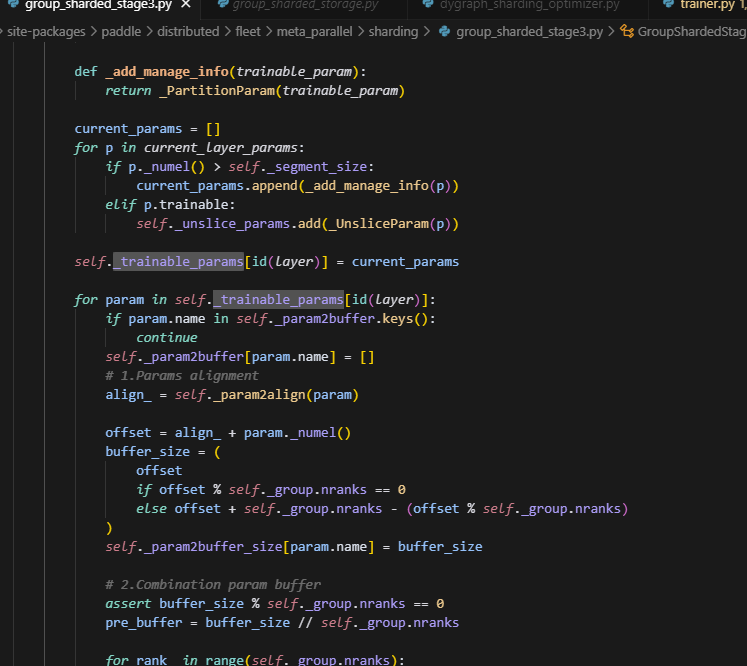
初始时,每个sharding_rank上都有全量的param,会根据segment_size决定是否切分param,如果param比较小,没有切分的必要,则每个sharding_rank都保留全量的param。否则就做切分。
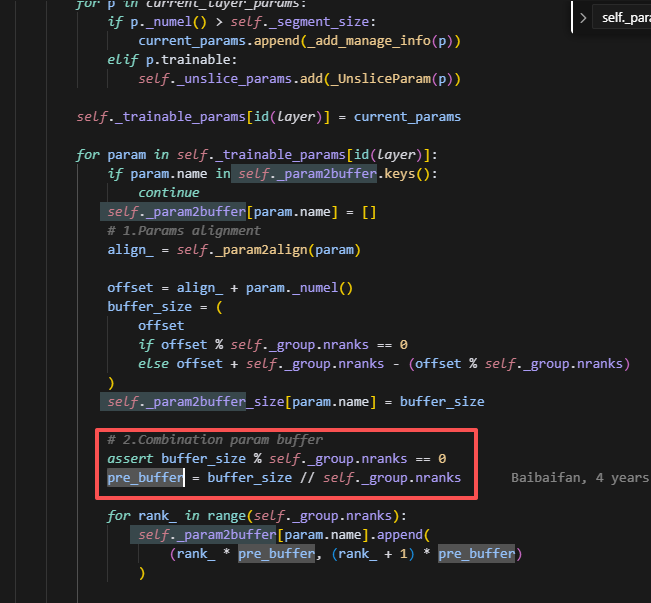
分到每个sharding_rank是均分当前的param,并且是经过padding后的,每个slice_param,并不存放在连续的param空间,而是分别单独创建了一个buffer,具体实现如下:
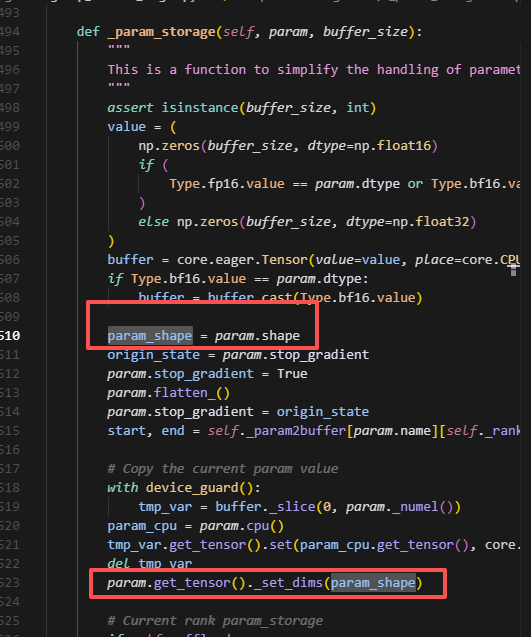
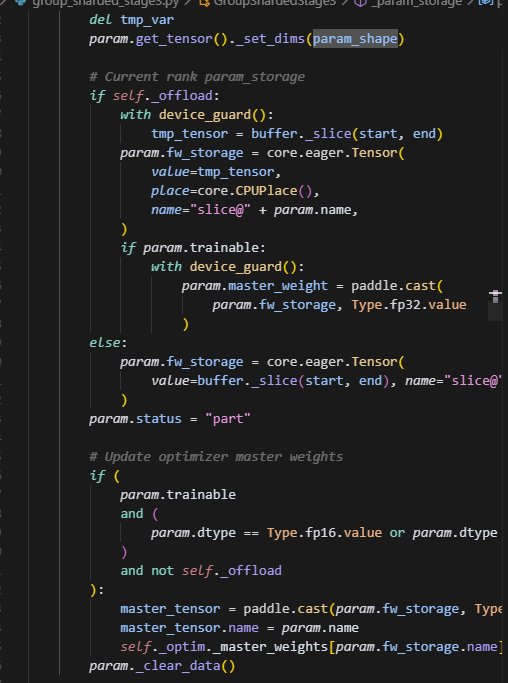
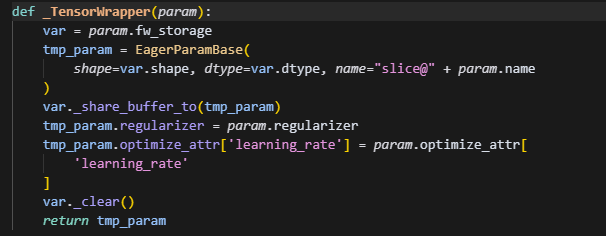
根据buffer_size创建一个tensor即为buffer,然后每个rank会分别做切片,仅保留当前rank上分片大小的参数。用param.fw_storage保存数据,最后调用param._clear_data()清空param的数据,但是注意,param的形状始终保持为多维数据,因此grad也一样。
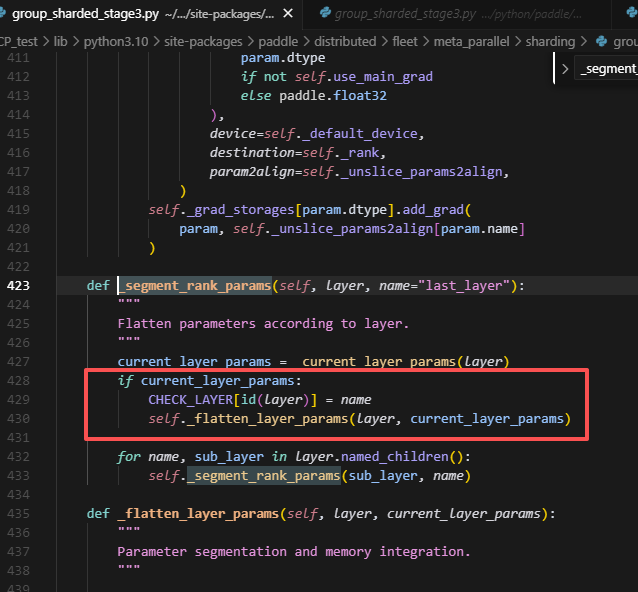
segment_rank_params会在最初初始化的时候调用,进而调用_flatten_layer_params
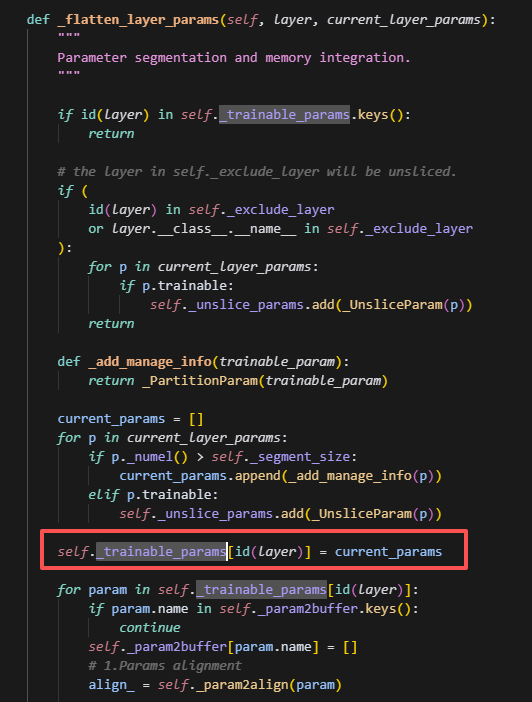
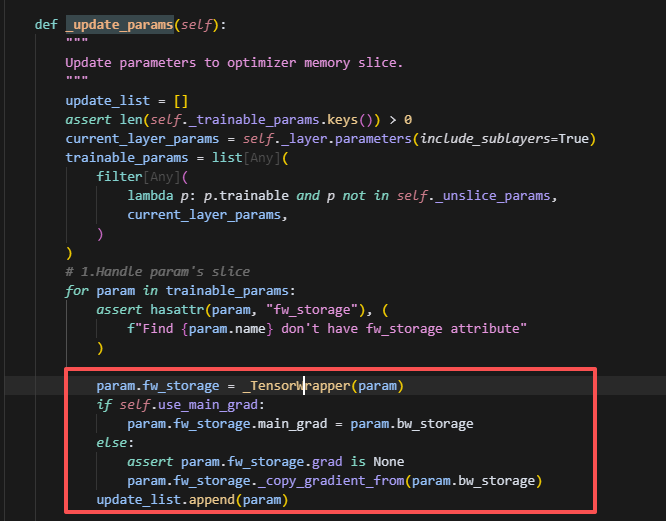
而_flatten_layer_params中则会记录self._trainable_params,self._trainable_params会根据layer_id,将每层slice的layer的参数一一对应记录下来,方便后续forward使用。
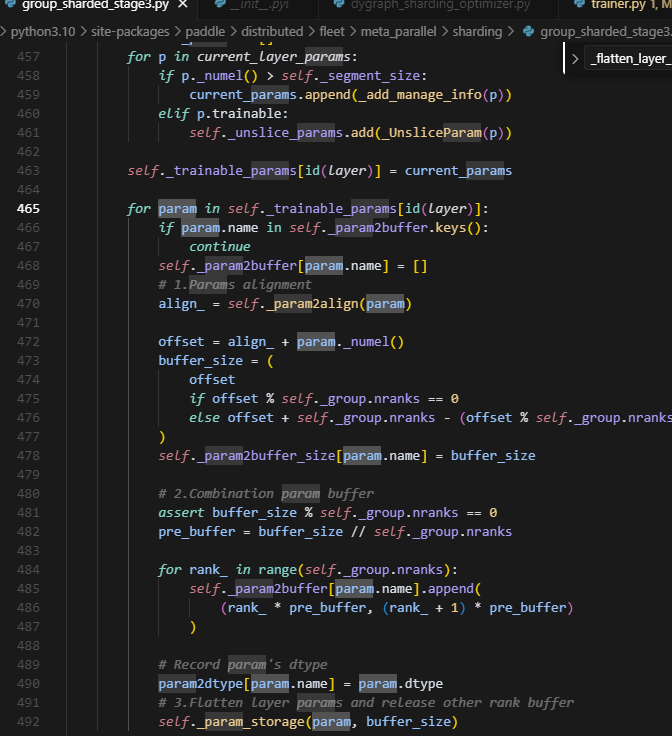
注意会遍历处理trainable_params里面的每一个param,并且调用了param_storage,则此时param原来存储位置的数据会被清空,而保存到param.fw_storage上。
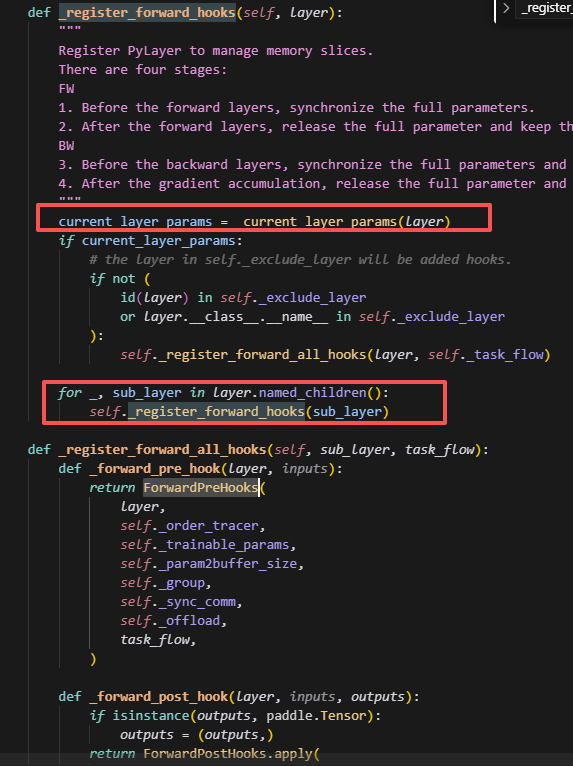
Forward时从最外层开始,逐步对每一层都创建forward的钩子函数。这里包含两个钩子函数,分别对应ForwardPreHooks,和ForwardPostHooks.apply。通过分别注册pre_hook和post_hook来控制两者分别在forward计算前执行和forward计算后执行。
ForwardPreHooks
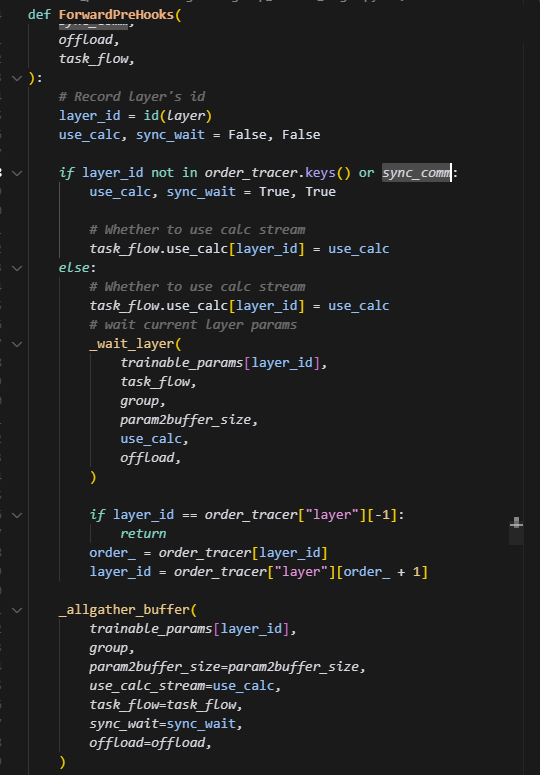
这里第一个hook主要是将slice的参数做一个all_gather从而获得全参,做前向的运算,task是一个底层通信库的异步句柄,用于控制什么时候去拿到full_param。这里会把full_param,task放到task_flow当中,这里_all_gather会立刻发起通信,将全量参数放到out中,但不一定立即完成。后续需要使用到当前param的全量参数时,会调用这个创建好的task,task.wait(),即阻塞等待allgather完成,从而获取full_param。
如�果是第一次执行,或者开了同步开关,则直接用allgather_buffer获取当前层的param,否则,调用wait_layer获取,然后layer_id通过order_tracer变为下一层,然后调用allgather_buffer去提前发起下一层layer参数的allgather任务。
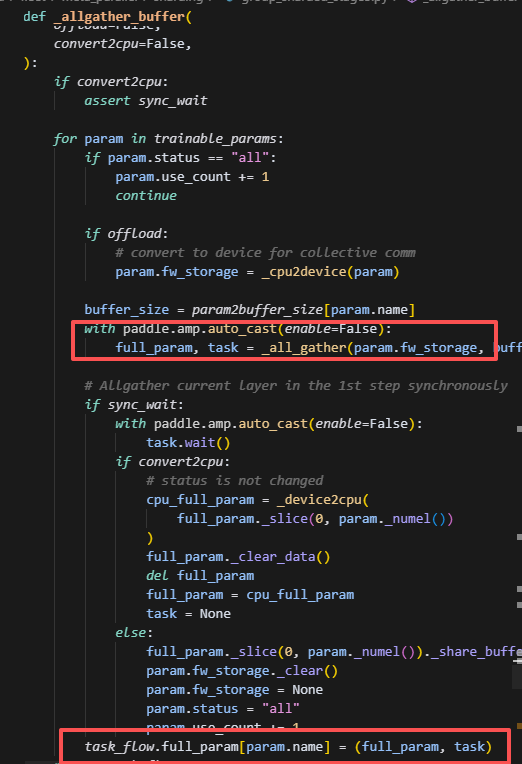
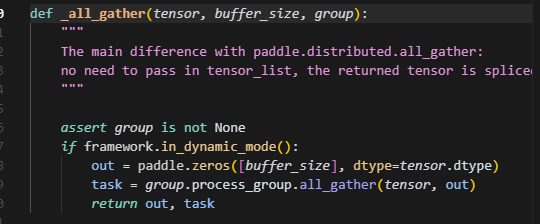
这里如果是首次调用或开了同步,则会进入同步分支,等待当前层的allgather通信全部完成,获取到full_param并做切片,即剔除padding那部分数据,然后赋值给param,并将param.fw_storage给清空,这里应该是为了节省显存,此时slice_param就不再是未初始化的状态,而是一个全量参数,并且去掉了padding部分,从而可以正常做forward。
ForwardPostHooks
forward_hook
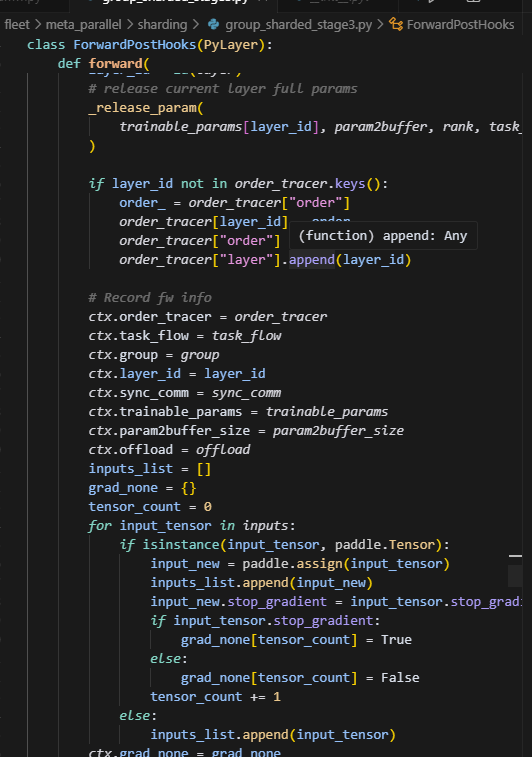
forawd结束后,首先会调用release_param对full_param进行内存释放,紧接着会记录forward的上下文,这里应该是为backward做准备。同时首次forward会更新order_tracer,order_tracer即用来记录layer执行顺序,并且根据索引获取layer_id。
这里用paddle.assign去创建一个新的tensor进行传递?
还不太清楚,初步原因感觉是PyLayer的机制,需要通过这个tenosr去建立forward和backward的连接。
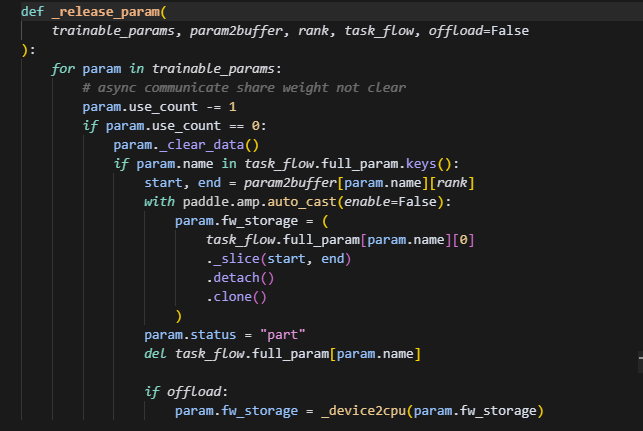
释放param的时候,首先这里clear_data只会清除param这个tensor对应的引用,并不会因为和full_param共享内存而清除掉full_param的数据,紧接着根据slice的切分范围,把full_param再分别赋值给param.fw_storage,最后释放掉full_param的内存。
backward_hook
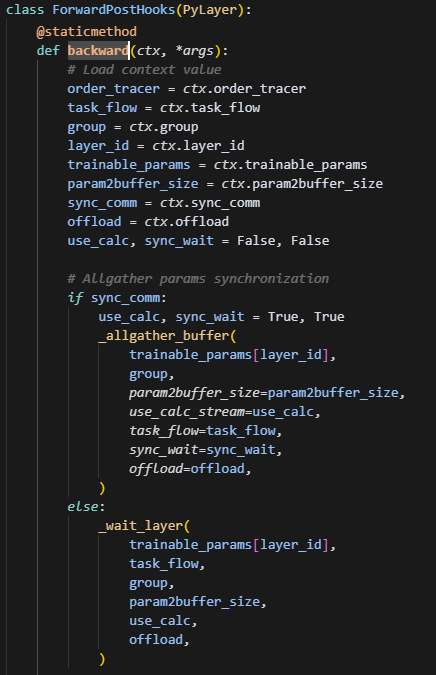
这里虽然是在forward过程注册hook,但是这个backward方法会在反向的时候调用,使用PyLayer统一管理,是为了统一上下文ctx的信息,这样在反向的时候,自动微分框架会在梯度计算前,调用该方法,为param.grad创建与param大小一致的空间来接收梯度,同时这里也可以在异步创建下一层的梯度。并且这里做了一个参数恢复,即在反向时,计算grad(output_grad,w,input)需要用到全量的param,因此会提前做一个allgather,将分片param做一个聚合,得到完整参数。而输入即上一层计算输出的结果,会在forward的时候自动保存,这里无需处理。
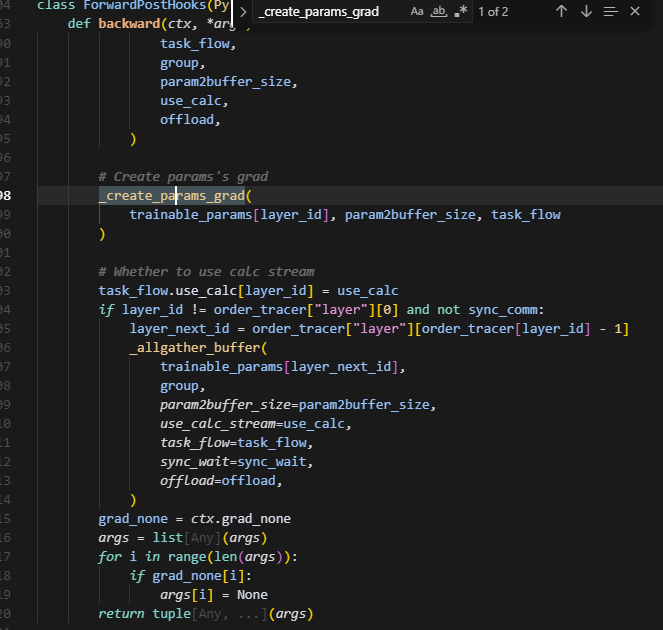
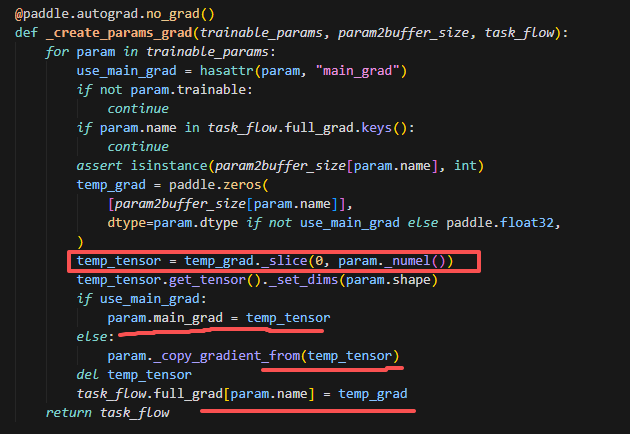
_create_params_grad这里是创建grad的逻辑,会对param.grad及进行初始化,大小与param大小一致。这里主要是为了计算当前层的grad之前,对param.grad做一次初始化。这里注意两个大小,因为param.grad是和param大小一致的,因此需要从full_grad中取出param大小��的那一片,和param.grad共享这一片视图,则后续通过自动微分框架进行backward,算出来的param.grad就会保存在这一片内存上。task_flow.full_grad保存的是padding后大小的grad,即这一整片内存,因为后续对多个rank做allreduce的时候也是对padding后的做,并且分片保存在bw_storage上的也是pandding后的数据,因为opt更新时,param和grad都是padding后的数据,但是forward正向计算时,需要param大小一致,这时候需要从full_param里面切出未padding的部分。
backward_hook
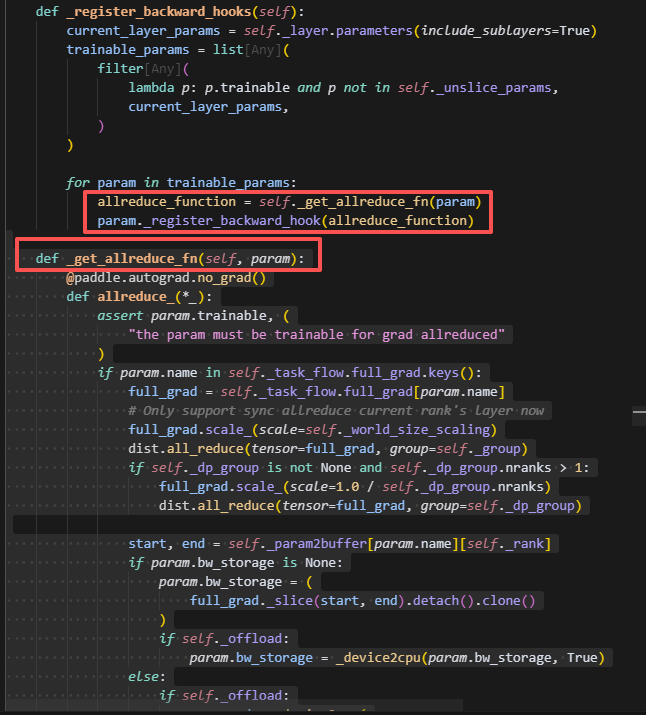
backward_hook主要用来对计算得到的梯度做一个allreduce,在这里会根据sharding_group进行all_reduce,同时如果额外存在dp_group,则会再次做一次allreduce,这里task_flow.full_grad是在前向时被0元素填充时保存的字典,而在反向计算时会自动存放到param.grad或param.main_grad,因此可以从这里取到每个rank的full_grad。并保存到param.bw_storage中。
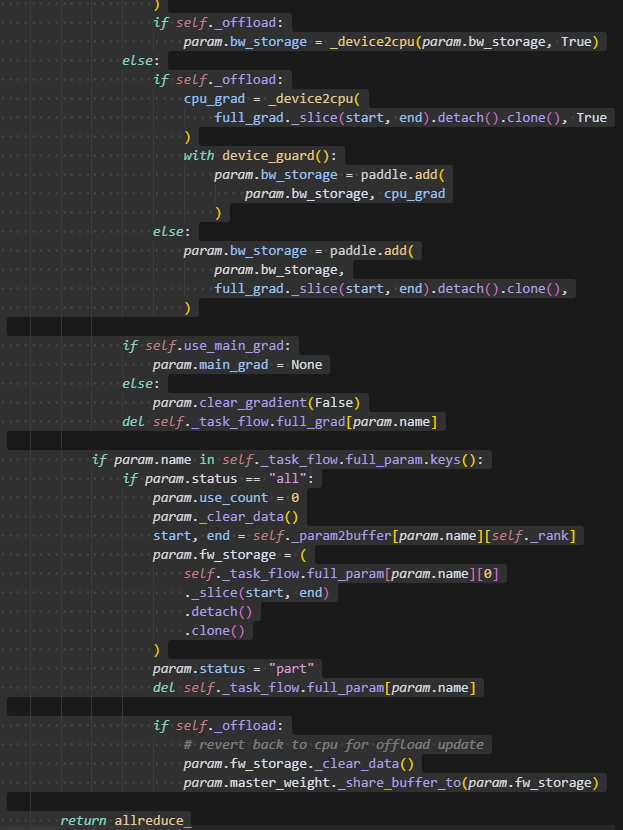
将更新后的梯度保存到param.bw_storage后,则会把原来的param的grad给删除掉,从而使grad保存成一个切分的状态。由于反向计算会用到前向计算的参数,即full_param,因此需要把刚刚allgather得到的整块参数再释放掉。这里保存到param.bw_storage的grad是经过padding后的数据。
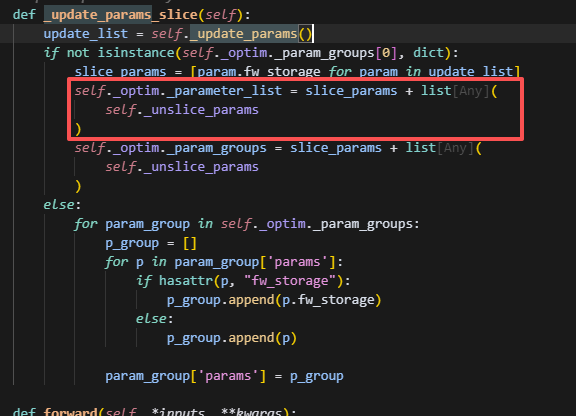
optimizer.update_slice = update_params_slice
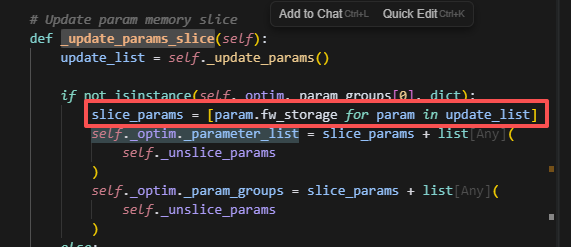
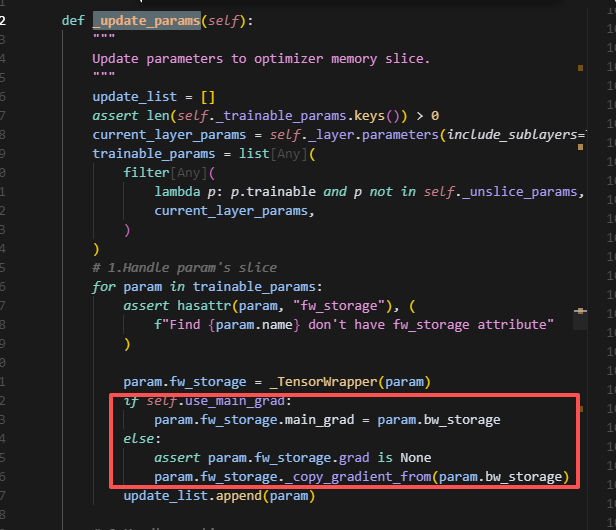
传入优化器的参数是padding后的参数。
所以,forward和backward始终使用的是原始param大小的数据,而优化器更新的时候,梯度和参数传入的都是经过padding后的分片参数,并且更新时也以分片参数的视角更新。因此优化器参数的大小,多个sharding_rank合并起来并flatten后,大小等于buffer_size,即padding后的大小。

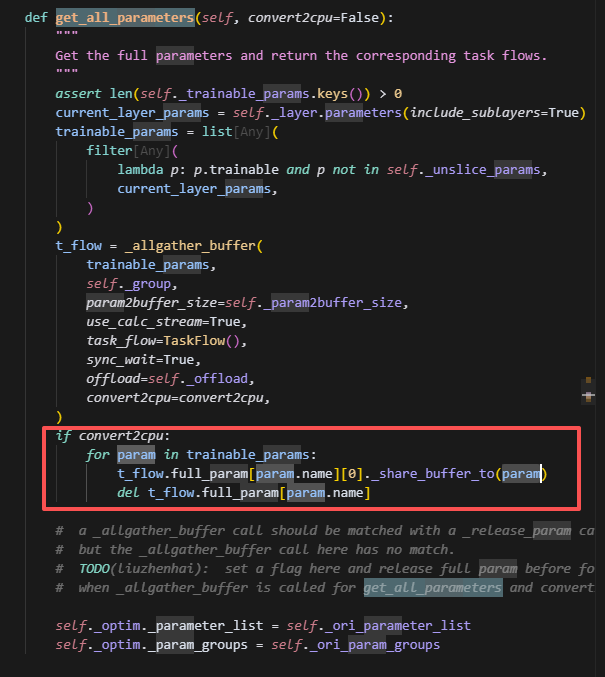
save的时候会把每个rank上的param_fw_storage给allgather,然后得到full_param,让param指向full_param(未padding的)。
update_params_slice调用时刻

update_params_slice方法会被封装给optimizer,而只有当要调用optimizer.step更新参数时,才会调用,因此,GroupShardedStage3()首次调用完毕后,此时optimizer的param仍然是原来的model_param,对应需要切片的param,则都是空值。因此load_fc的时候,不仅需要重新初始化这些参数,并且要根据param.fw_storage进行初始化,因为在GroupShardedStage3下,optimizer中被slice的参数,始终都是一维的,而最开始因为没有调用update_params_slice,导致其形状还是多维的。
一个重点:shardingstage3的model和optimizer写在一块,
这里参与计算的优化器底层虽然是Adamw,但是在shardingstage3中被封装了一层,用的下面这个wrapper,醉了,因此每次计算optmizer的优化器状态参数,其实在shardingstage3的self.opt里面,如果直接调用Adamw的shard_state_dict,是不行的,因为Adamw的优化器状态参数其实是并没有参与运算的,因此需要给shardingstage3里面的opt新增一个shard_state_dict方法。
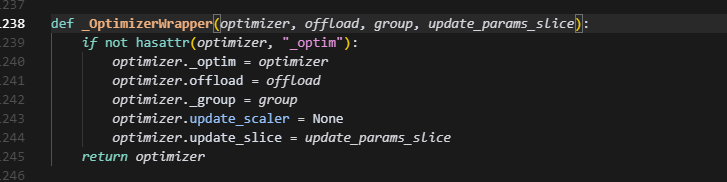
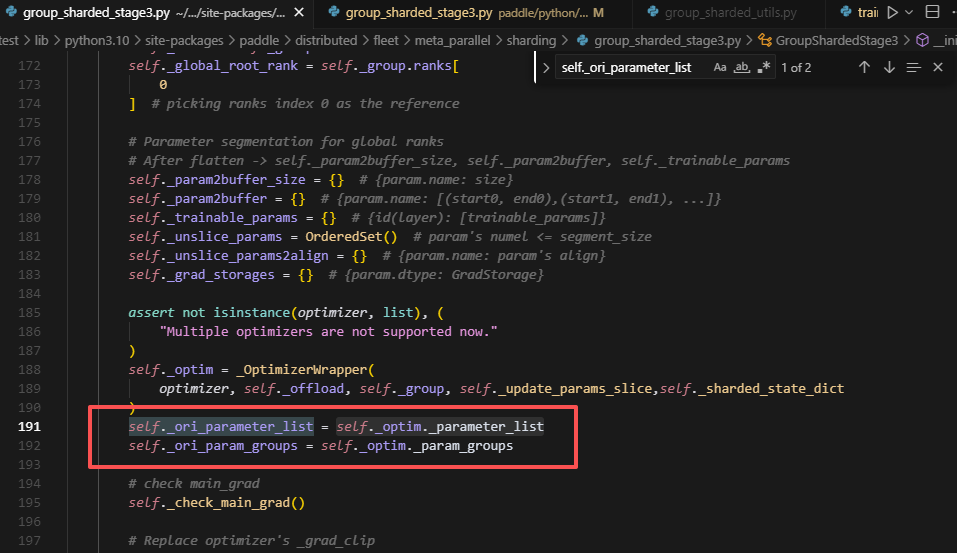
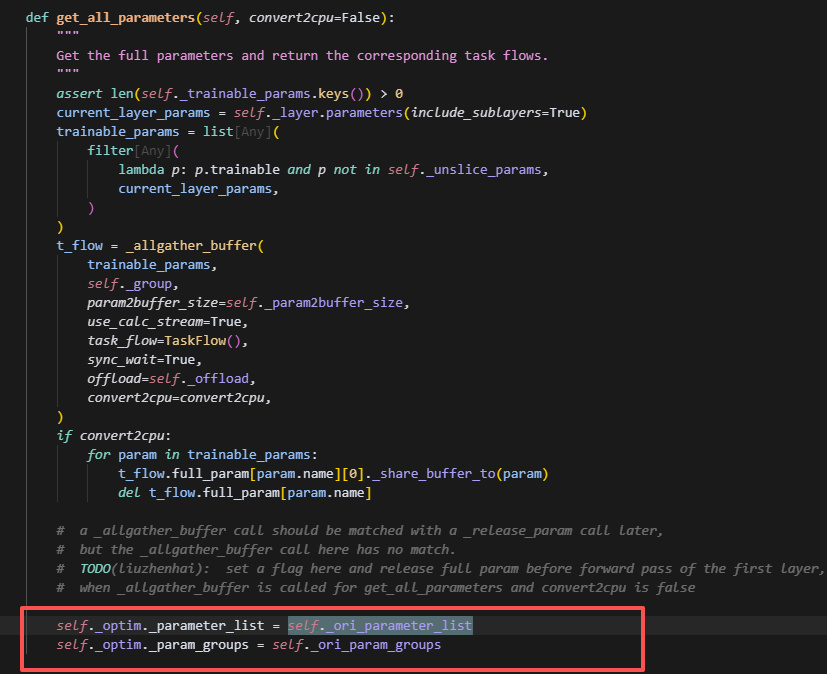
最后拿全量参数的时候,搞了一个这个操作,去获取最开始的参数列表,感觉是想让opt的parameter_list和model的param格式对齐,但感觉毫无意义。
重点分析optimizer的param_list和state_dict
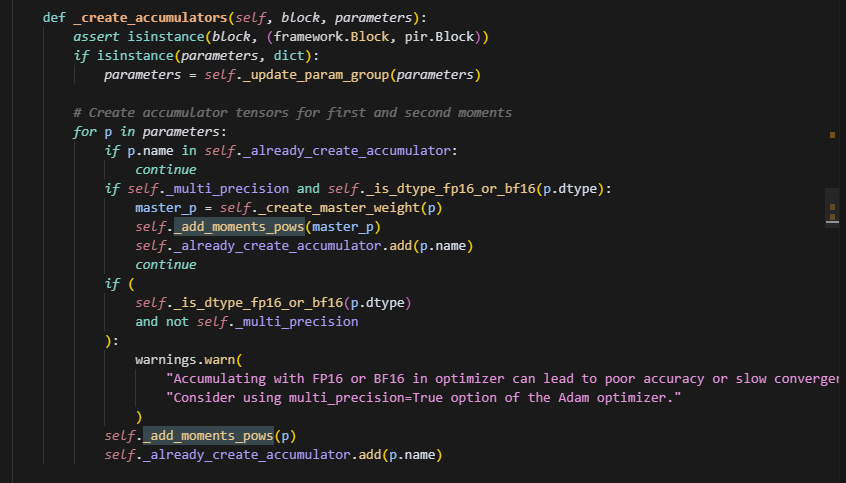
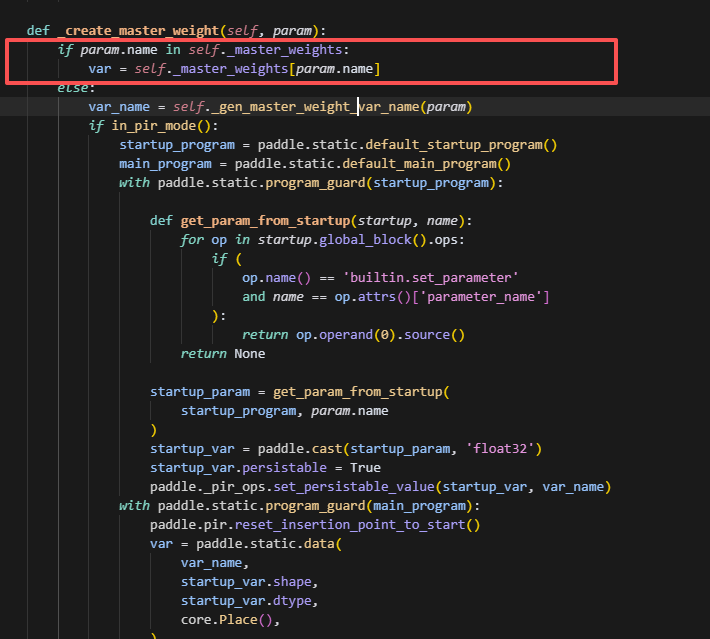
创建优化器状态时,如果是混合精度,则会根据optimizer的parameters先创建master_weight,此时param已经在master_weights的列表中了,则直接取var,否则在动态图模式下,会给它cast到float32,并且,名字后缀会加上"_fp32_master"。
如果是非混合精度,则直接用param去创建优化器状态,不需要创建master_weight。
创建优化器状态,即使用add_moments_pows:
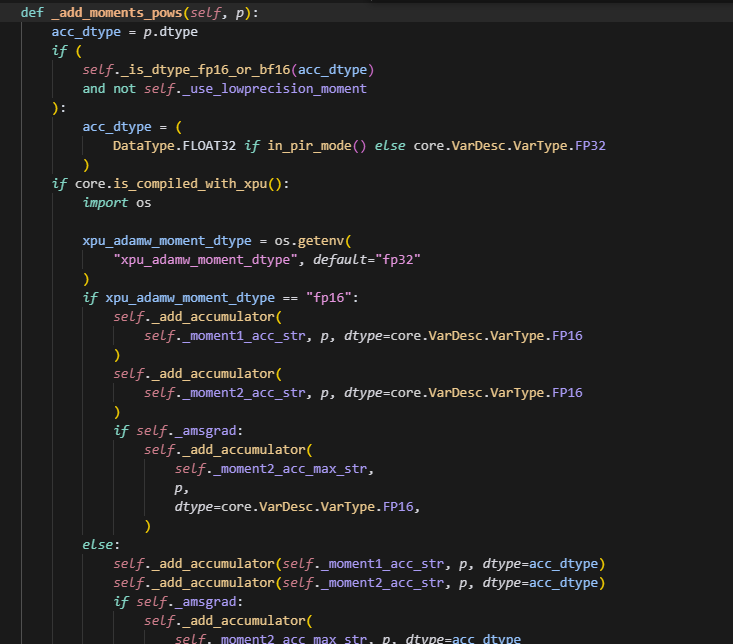
在这里,会调用add_accumulatoer来分别创建moment1,moment2,beta1,beta2。
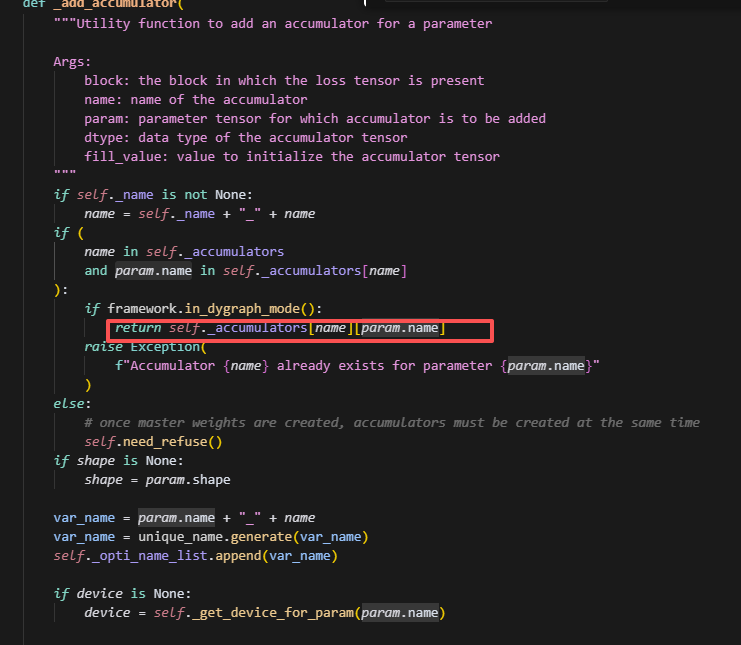
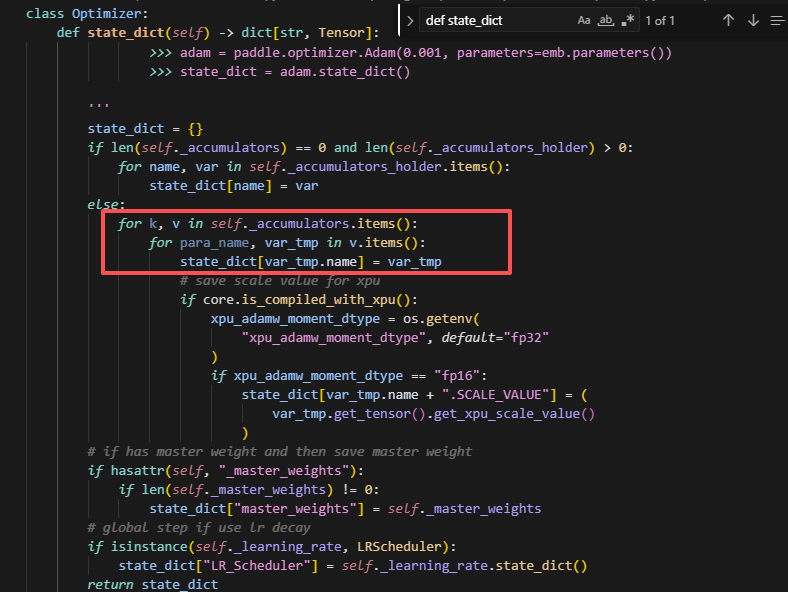
在这里会把优化器状态加入到accumulators中,并且后续优化器参数的更新和维护都在这个表中,而后续调用optimizer.state_dict()也会从这里面去取优化器状态的所有参数。state_dict里面保存的tensor,key是value的name。
Shardingstage3中存在的特殊问题
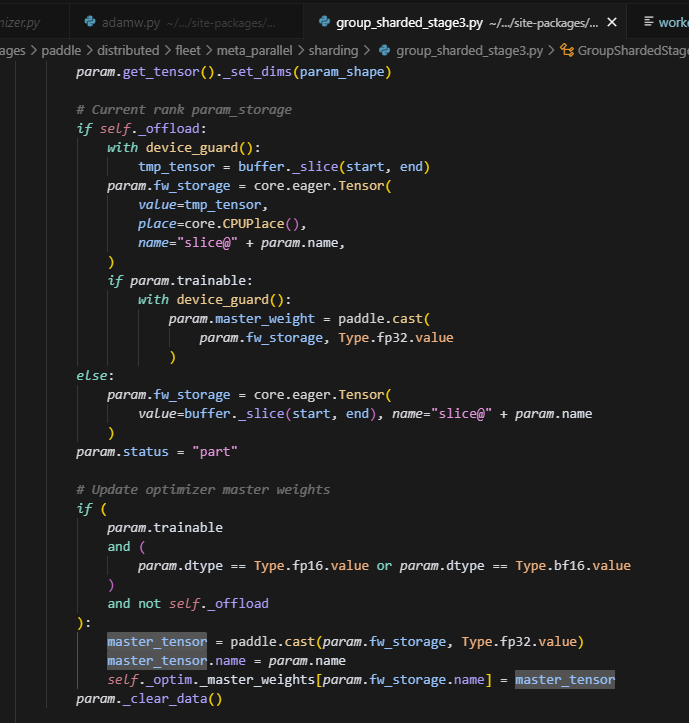
Stage3在初始化,将param移到param.fw_storage的时候,手动更新了self._optim._master_weights列表,而注意,这里用的master_tensor.name是不带slice@的,这就导致后续创建的优化器状态的参数是不带slice@的。
而如果是非混合精度的情况,会直接用param.name,而从下图可以看到: