ShardingStage2_Zero2
分为GroupShardedOptimizerStage2与GroupShardedStage2,前者会服务于后者
1.GroupShardedOptimizerStage2
segment_params
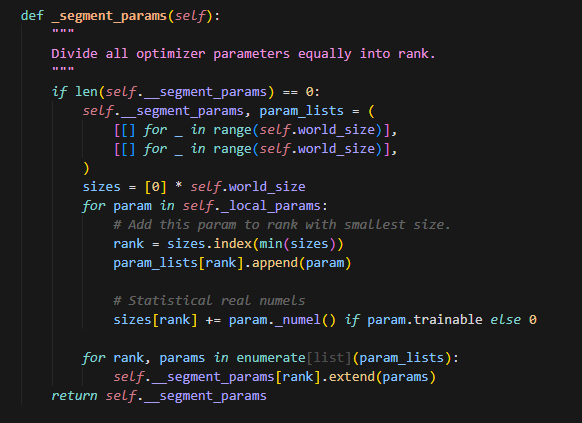
可以看到,这里切分param采用和ShardingV1同样的方式,会按照负载均衡的思想给每个rank上分别分配参数。
dtype_rank_param
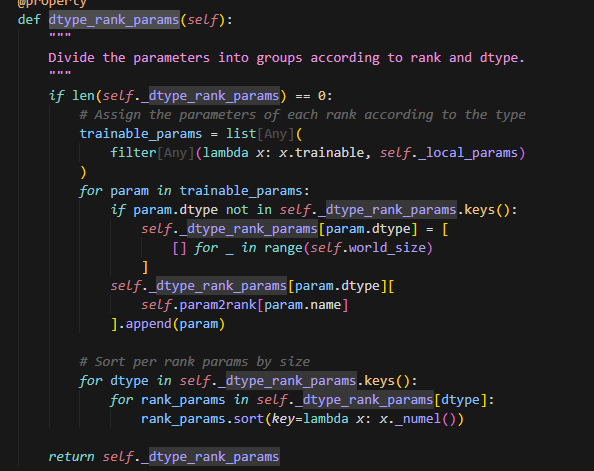
根据dtype再将每个rank上的params再做一次划分。
rank_buffer_size
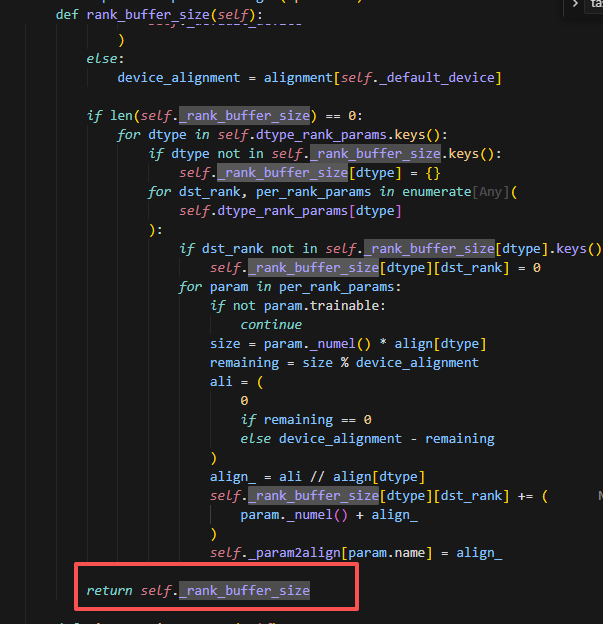
保存每个rank上对应dtype的所有param经过padding后的大小。
integration_params
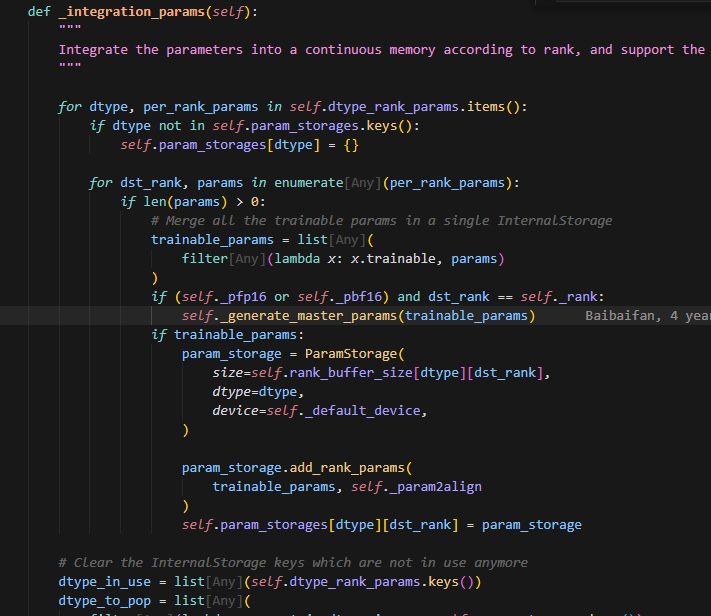
根据rank_buffer_size来创建每个rank不同dtype的params组对应的storage。这里创建的storage是一个ParamStorage的实例,即创建一个buffer_size大小的实例,这个实例包含来当前rank某种dtype的所有param经过padding后的大小之和,根据这个size创建后,得到一个连续的内存空间。可以调用add_rank_params来将每个param连续地放到这个存储空间。
add_rank_params
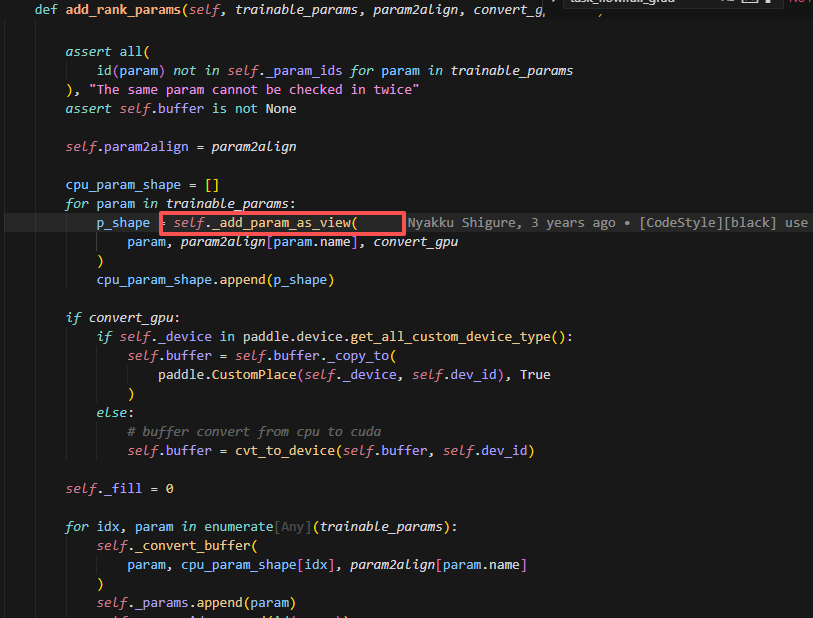
这里会将param给放到对应的buffer组中,从而将一组离散的param视图,转换成一个连续空间上的param视图
_add_param_as_view
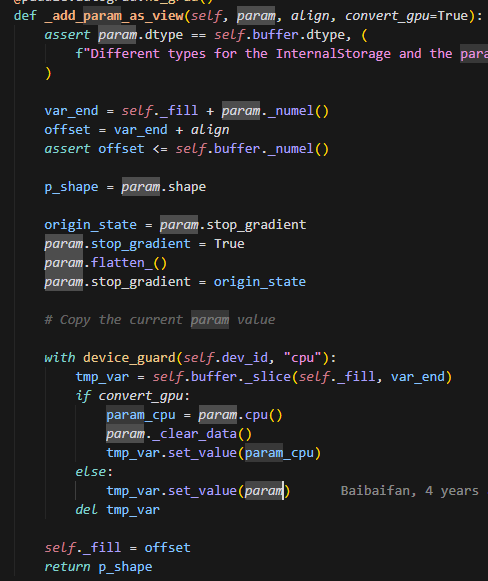
这里会调用param.flatten_()把参数展平,然后将对应的数据复制到当前buffer的对应位置,padding部分无需复制。这里展平是为了和buffer的size对齐。这里会记录param.shape,将param的值拷贝到buffer上后, 会立即恢复param的shpae,通过param.get_tensor()._set_dims(p_shape)
param.flatten_()
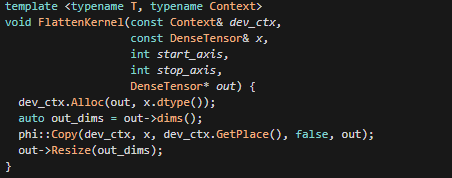
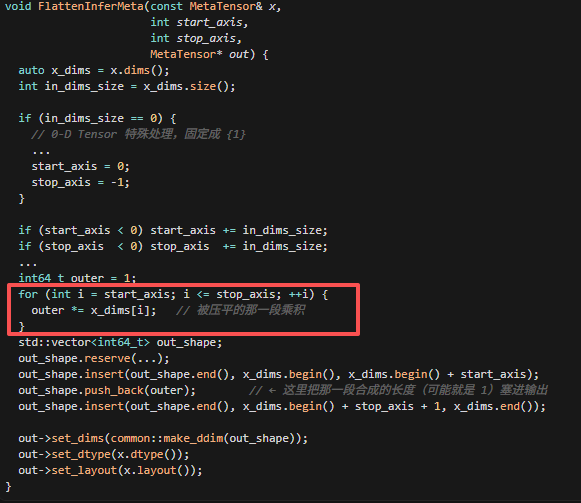
这是flatten的kernel,其实是组一个reshape的操作,即将param的shape转换成一维的,这里虽然会调用Alloc,但是这个reshape操作不会改变param的shape大小,所以一般不会新分配内存,这里要返回的是out,Copy即会将out指向和x指向的同一片区域,并且此时out的dims设置成一维大小。这里的out->dims就是调用flatten过程中,会遍历x_dims,做乘积,从而将多维展成一维。
broadcast_params
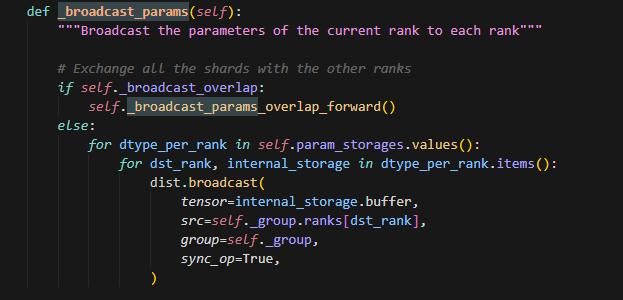
这个函数会在opt.step后调用,主要是为了将sharding_rank更新的参数做一个allgather,因为不同rank负责更新不同的参数,所以每个rank去广播自己更新的参数即可。
目前Stage2的实现,是怎么实现optimizer参数的划分的?
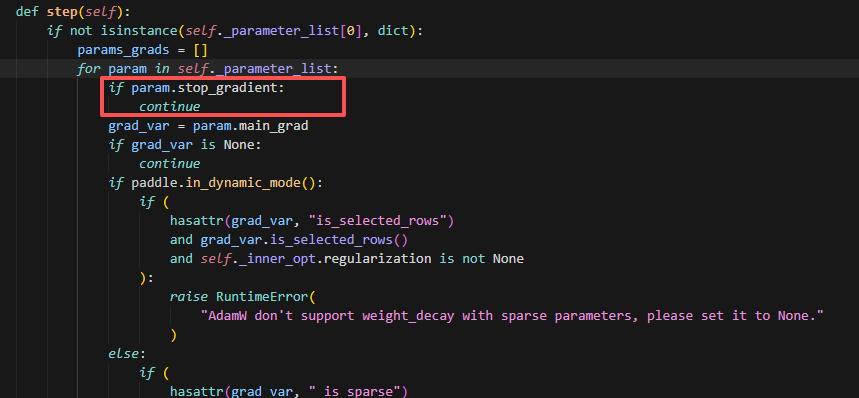
其实是因为在GroupShardedStage2中,为了划分grad,会把非本rank上需要处理的参数的grad给清除,而此时grad为None,就不会参与创建优化器状态与V1不同。
stage1V1和stage2都是对param进行负载均衡分配,但是控制优化器参数划分的方式不一样
stage1V1是通过每个optimizer中只传入对应rank需要处理的pram,来初始化优化器
stage2是通过将非本rank的参数的grad清除,再初始化优化器参数,此时由于grad为None的param是不会初始化优化器参数的,因此达到划分优化器状态参数的目的
2.GroupShardedStage2
_setup_use_grad_storage
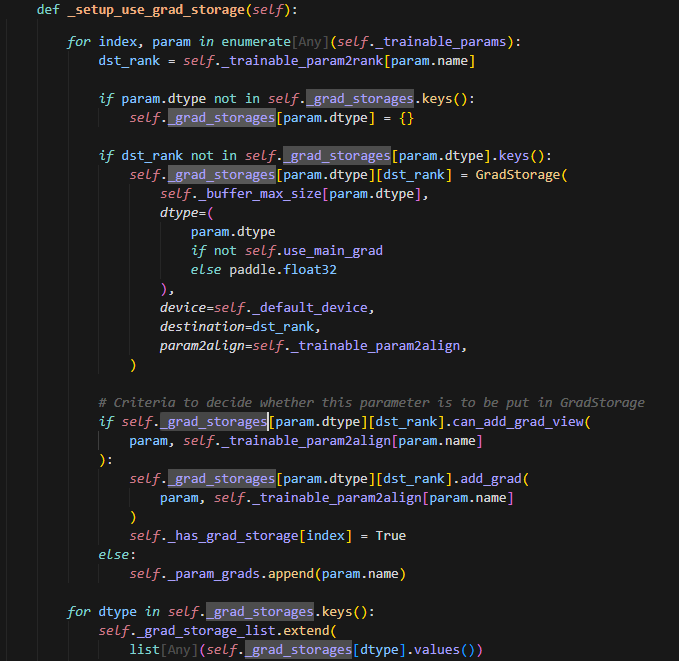
为相同dtype相同rank的pram创建grad_storage,此时每个sharding_rank都会创建全量参数的GradStorage。
get_reduce_fn
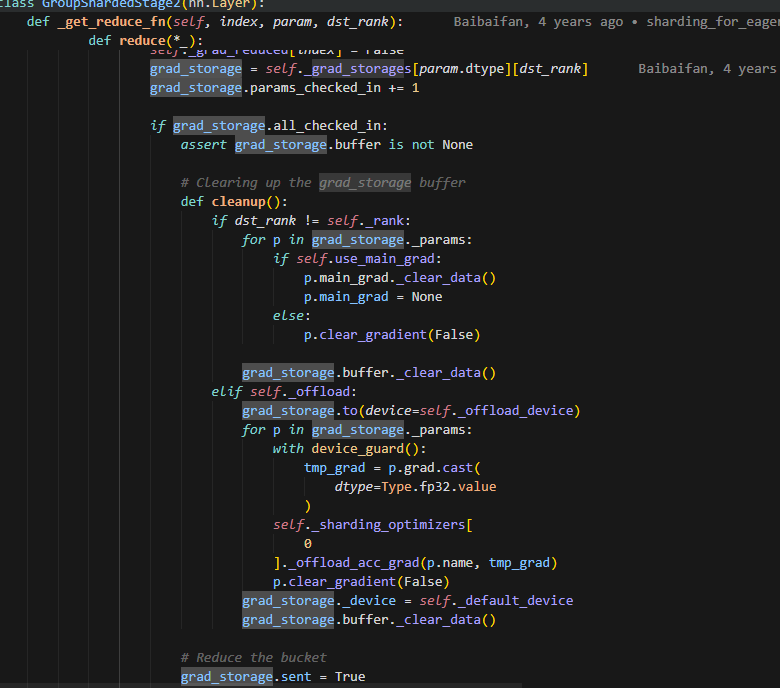
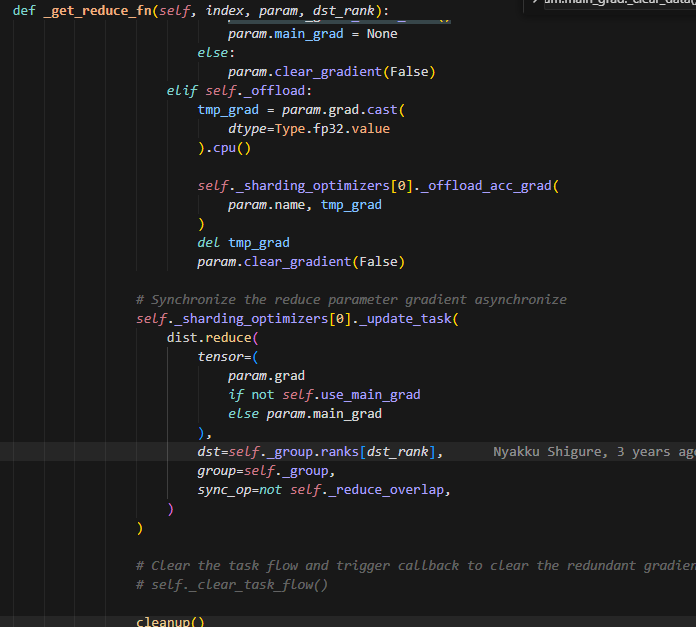
在这个参数当中,会有一个cleanup的操作,即如果不是当前rank的参数,则会把grad给清空。这里会调用reduce,则每个rank上计算得到的grad经过reduce之后,发送到对应处理改param更新的rank上,做梯度更新。
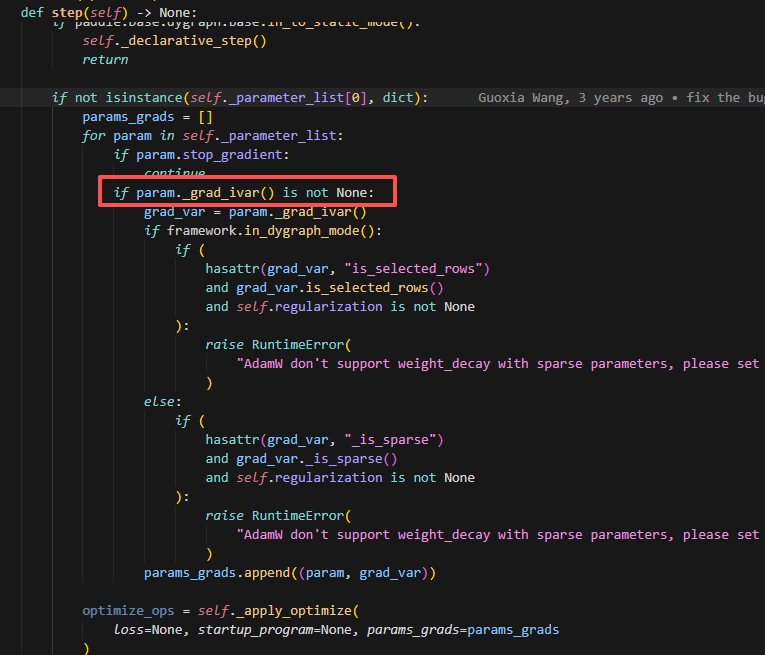
而只有grad不为None的参数才会与优化器参数做计算,因此通过这样的方式来控制每个rank上只做本rank参数的优化器更新计算。