ShardingStage1_Zero1两种��实现
DygraphShardingOptimizer简单介绍
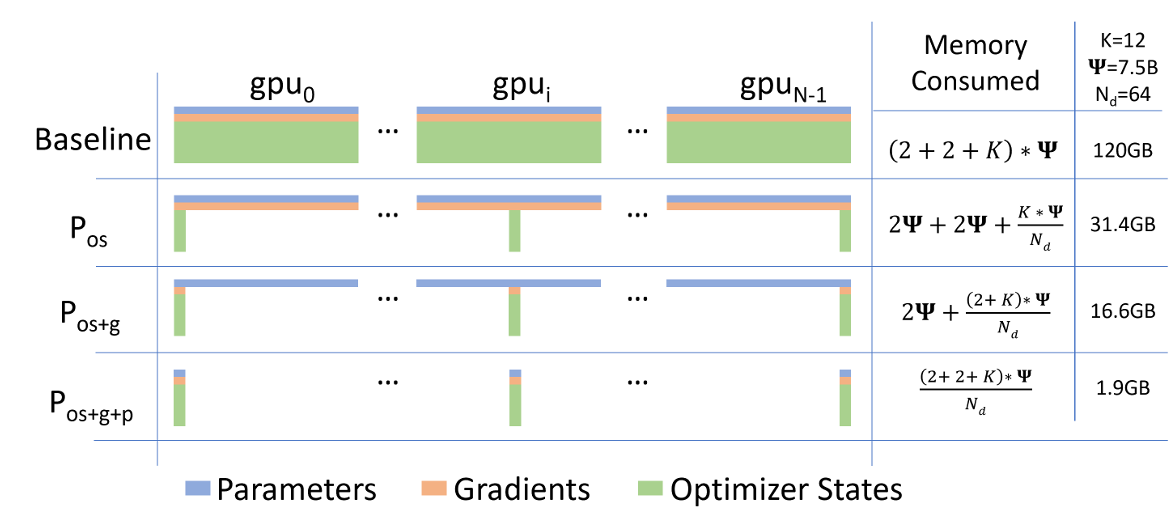
ZeRo是由DeepSpeed提出的优化方法,一开始主要是为了缓解DP场景下的显存压力。分为:
ZeRo-1: 优化器状态分片
ZeRo-2: 优化器状态与梯度分片
ZeRo-3: 优化器状态、梯度和模型权重参数分片
当前paddle中实现的DygraphShardingOptimizer和DygraphShardingOptimizerV2的思想和Zero-1的思想是相对应的,即仅仅对优化器状态进行分片,分摊到不同卡上。
1.DygraphShardingOptimizer
主要划分param的方法如下图所示(划分前可以选择是否对param按大小排序):
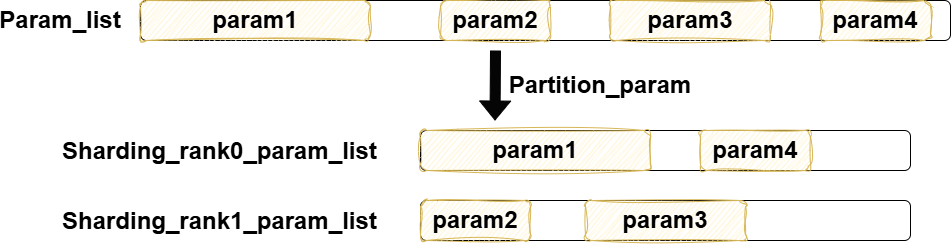
这里注意,首先,param的划分,是参数间的划分,不会对一个param内部去做切分;其次param在内存中可能是非连续存储的,并且这里分配param,仅仅做param到rank的映射,并不改变param在内存中存储的位置。对于DygraphShardingOptimizer的参数划分比较简单,其��重点在于两个操作,tensor_fusion和communication_overlap,因此在后续主要介绍这两点。
1.1 tensor_fusion
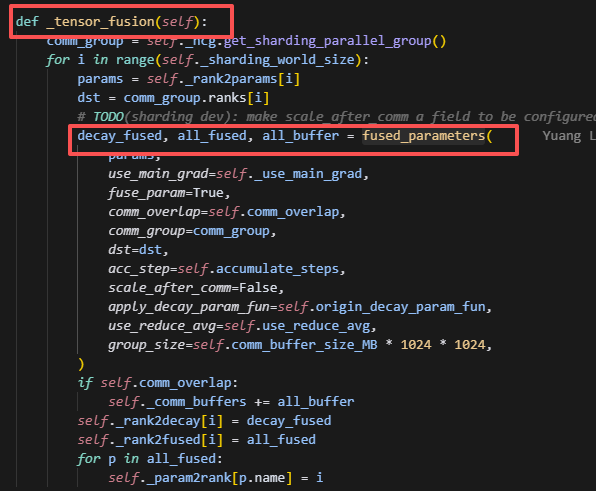
为了提高整个计算效率,DygraphShardingOptimizer可以选择是否做参数聚合,整个调用链路如下:
_tensor_fusion -> fused_parameters -> _fused_parameters_impl -> obtain_storage -> 创建FusedCommBuffer
而聚合的param列表,在聚合前,会经过不同类型做层层筛选,筛选流程如下:
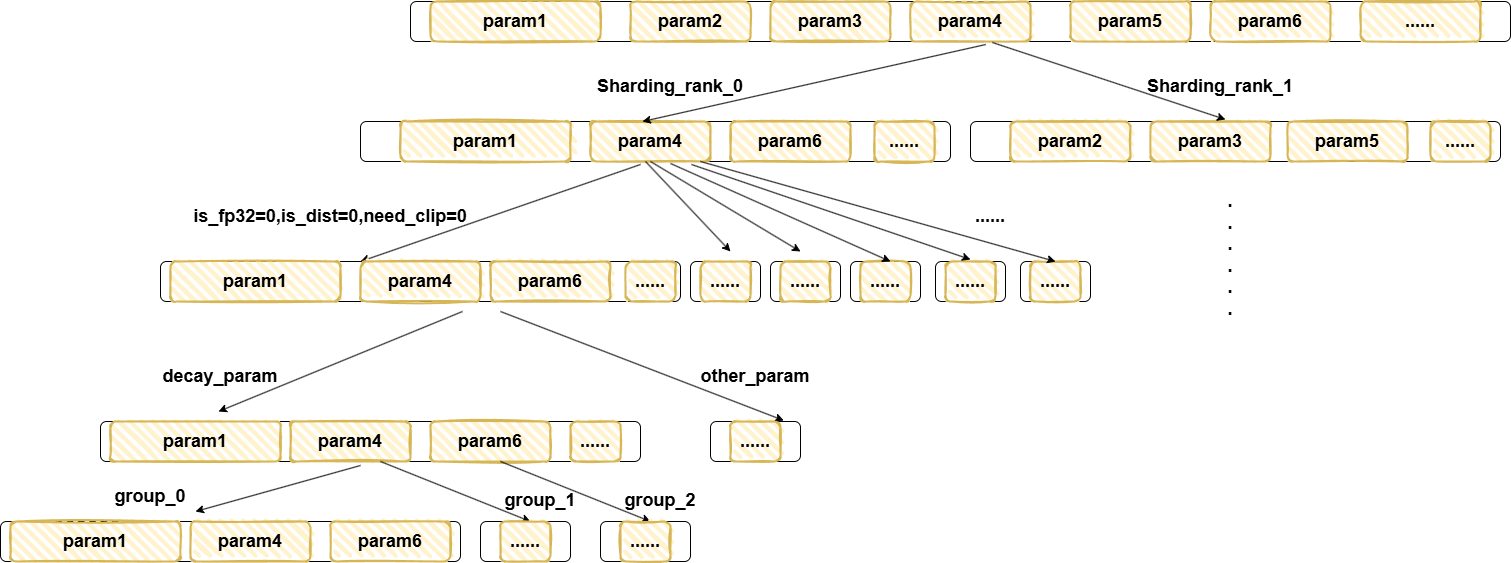
先根据sharding_rank划分,接着根据dtype、dist、need_clip等属性划分,再根据是否是decay_param做划分,最后会根据设定的group_size,使用贪婪算法,即每放满一个group,就另外新建一个group放置param。而聚合param,主要用到的类是FusedCommBuffer,注意当前rank上的所有group包含的param,只有当前rank上分到的param,因此FusedCommBuffer处理的也仅仅是当前rank对应的param,而这一点会和DygraphShardingOptimizer有所区别。
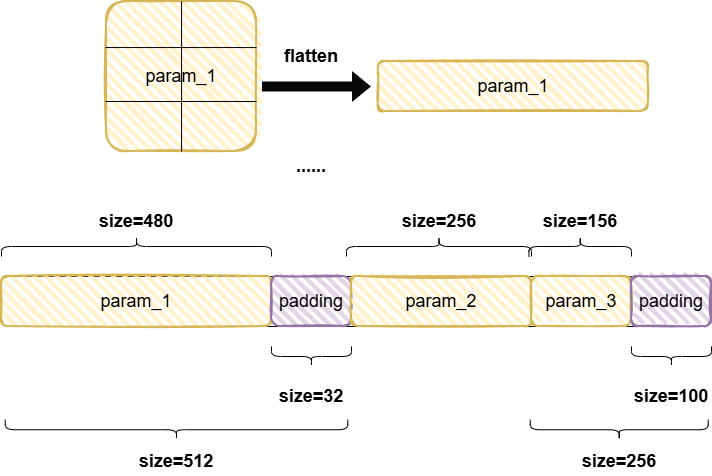
FusedCommBuffer这个类的主要作用其实就是为了将同一个group的所有param给放到一个连续的内存上,首先它会将param的维度展开摊平成一维,接着乘以dtype对应的字节大小,得到整个param对应的字节大小,紧接着进行内存对齐,目前gpu,xpu,npu都是256(这里做内存对齐的主要目的是提高内存访问效率)
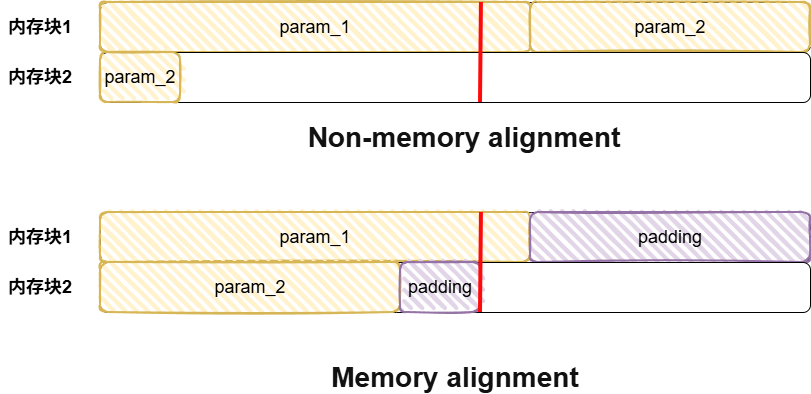
如上图图1所示,如果不做内存对齐,可能访问一个param要连续访问两个内存块,而如果做了内存对齐,此时只用访问一个内存块,提高了访存效率。
这里做了param对齐后,接着同样会对grad也按照上述方法做对齐,将grad也放置到一个连续的内存空间,buffer大小和param_buffer的大小是一样的。(注意这里提到的参数与参数梯度,都是optimizer_param_list中的参数,而实际每个rank上的model的param仍然都是全量的,只是优化器视角,以及后续创建的优化器状态是会划分了的)。
1.2 comm_overlap

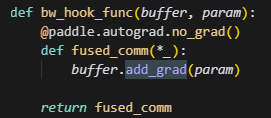
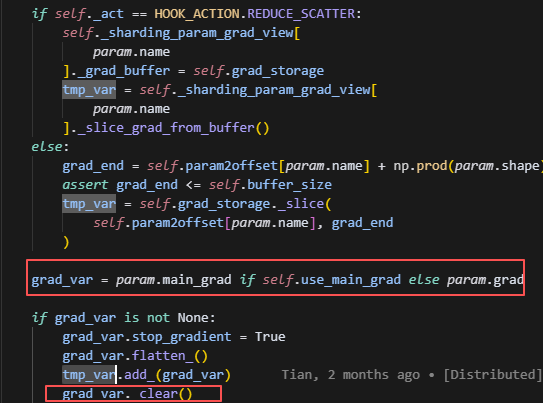
这里如果设置了通信重叠,则对于每个param,都会注册一个backward的hook,在反向过程中,每当当前这个param的grad计算完成后,就会立即触发hook,做add_grad操作,而add_grad操作主要作用是对计算好的grad做grad通信,其中如果设置了release_grads,则每次调用buffer._comm_grads后,都会清除掉当前的grad_buffer,因此,在add_grad中如果判断设置了release_grads,则会调用_copy_grad_to_buffer函数,再次初始化grad_buffer,并将新一轮的grad映射到grad_buffer上。
这里需要注意代码:


如果设置了acc_step,则会不断累积,当Fusedcommbuffer里的每一个param都做了acc_step次反向后,才会做一个grad通信,而在acc_step次之前,每一次计算得到的grad,会通过add_操作,进行累积。
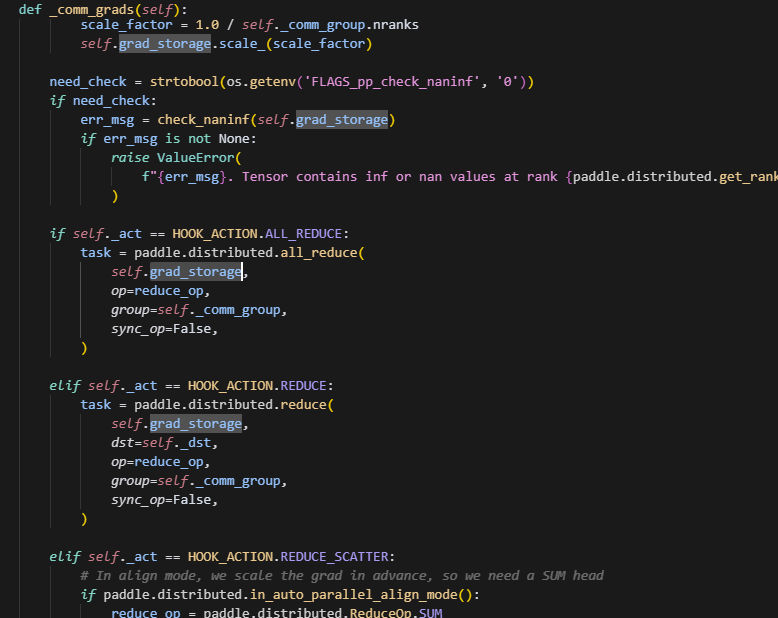
通信时,可以根据reduce_op,选择是做average还是sum;同时也会根据act来选择做ALL_REDUCE、REDUCE、还是Reduce_Scater。comm_overlap场景下,comm_group为None(默认在sharding_group中通信)时,只能用ALL_REDUCE。这里会直接更新grad_storage的数据,其实就是grad_buffer。而因为param.grad的内存已经映射到了grad_buffer上,因此会直接同步更新。
1.3 总结总体流程图
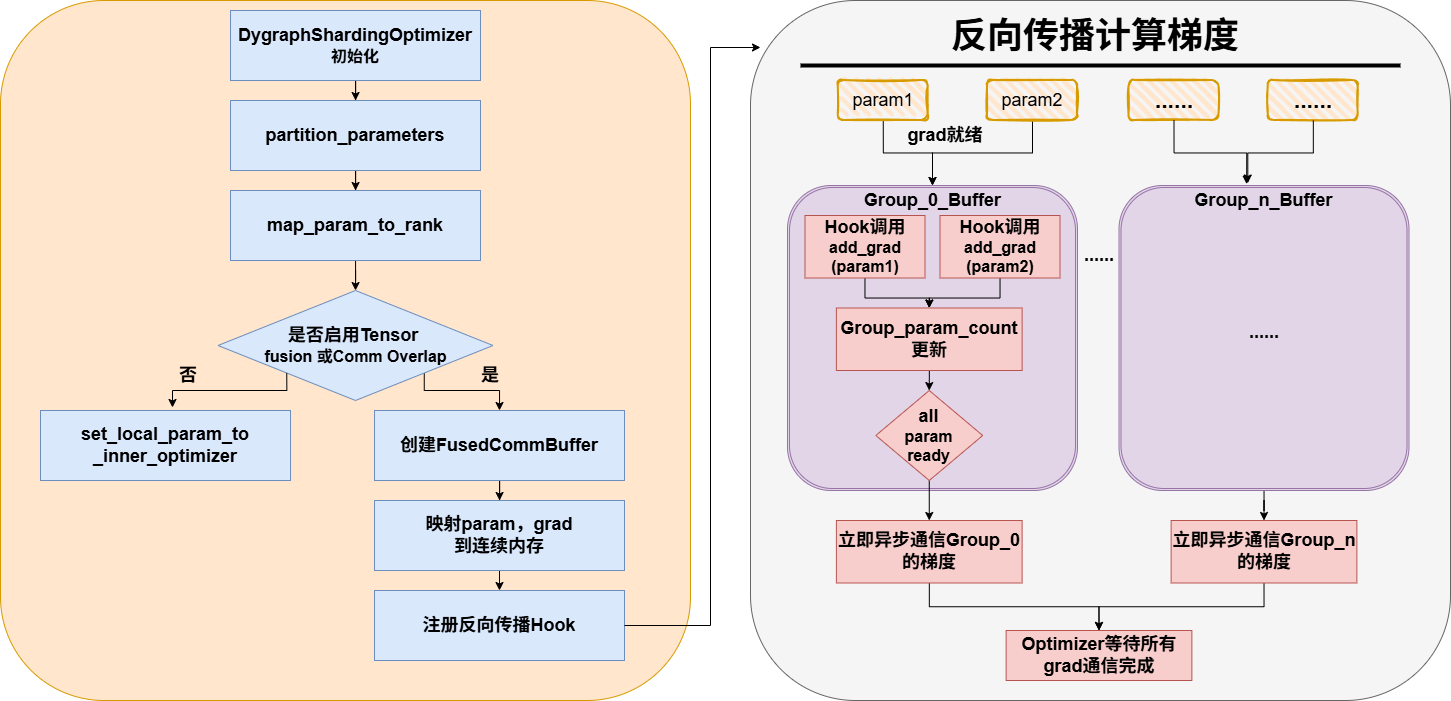
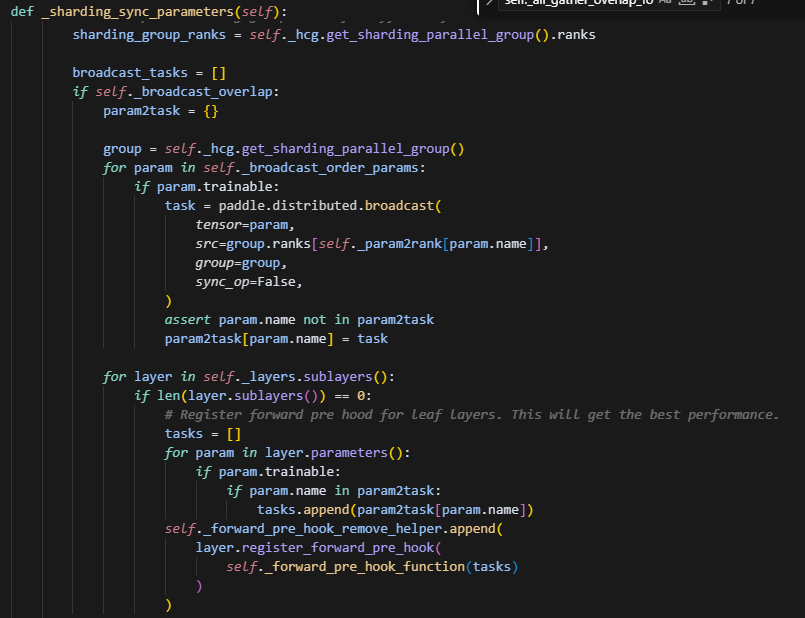
最后optimizer获得需要的grad后,会进行参数更新。最后在_sharding_sync_parameters中,使用broadcast通信做参数同步,这里也可以选择broadcast_overlap,给layer_forward注册hook,则当前layer只需要等待它所涉及的参数全部更新完毕,即可立刻开始做forward。注意只给leaf layers注册即可,因为它是最先实际执行完它自己整个的forward的,而它的parent_layer都依赖于它计算出的数据结果
2.DygraphShardingOptimizerV2
V2与V1的主要区别是V2会将当前group中的所有param全部展平成一维,再做均匀切分到每个sharding_rank上,因此V2是有可能切分某一个param的,即该param会存在多个分片在不同的sharding_rank上,这是与V1最大的区别,而这个展平操作其实也会间接做fused_tensor操作,因此V2是不需要设置fused_tensor的,其核心代码入口主要如下:
build_comm_buffers:
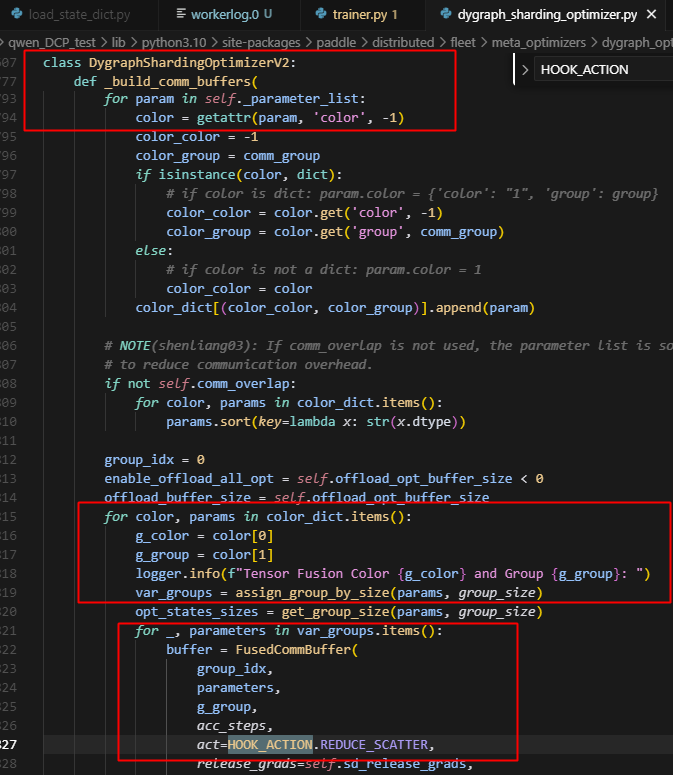
注意,这里每个FusedCommBuffer中的params同样不是全部的params,而是先根据color划分(这里的color其实可以是一些区分param的属性,比如moe等等),再根据group_size (固定值2**28)分组,得到多组params,这个和V1中是类似的,然后每一组params会创建一个FusedCommBuffer,对这组params进行sharding分片。
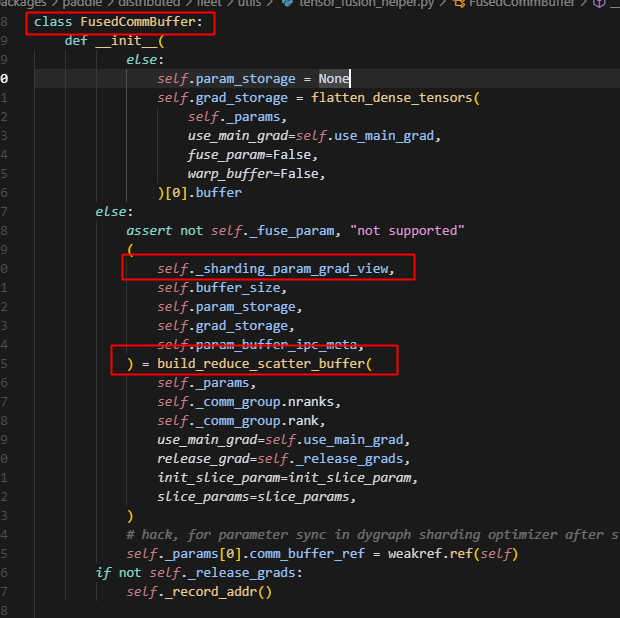
同时注意,此时的hook_action是reduce_scatter,因此实际会调用build_reduce_sactter_buffer函数;因此我们继续看build_reduce_sactter_buffer函数。
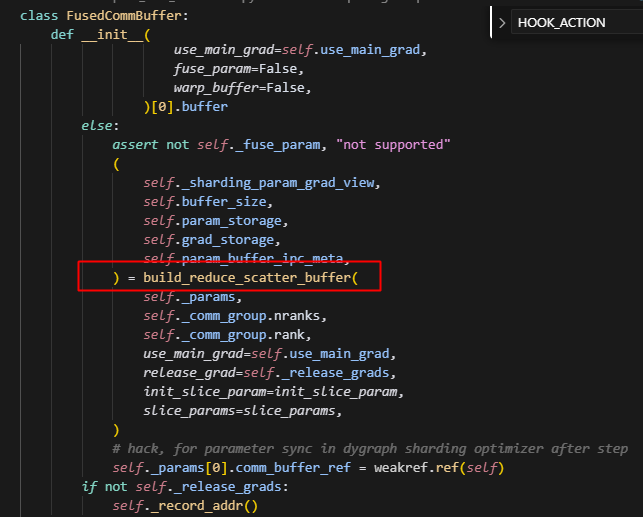
sharded_state_dict获�取param的分片信息,通过buffer的sharding_param_grad_view:(这里是shared_state_dict用到buffer信息,我们先看后文解析)
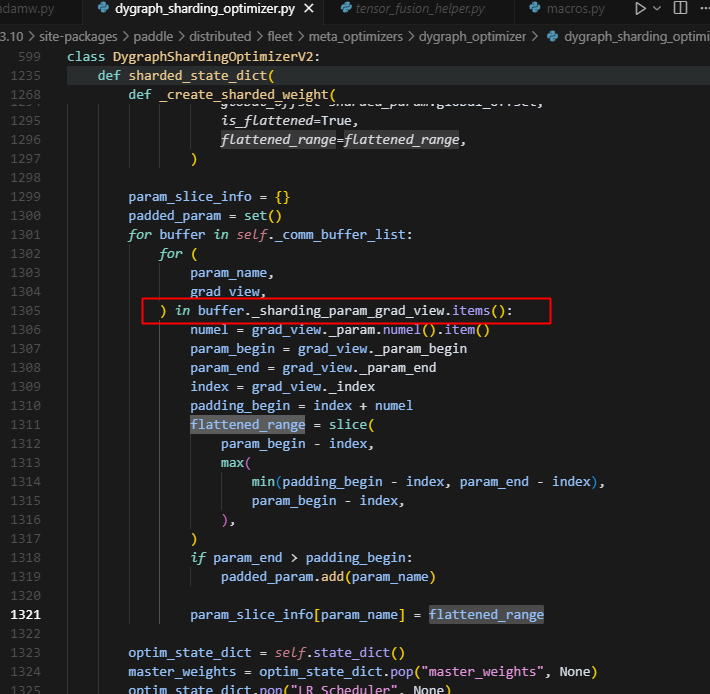
可以看到sharding_param_grad_view中保存了多个ShardingGradView实体,而每个ShardingGradView实体的信息,都能体现当前param的是如何被sharding到每个rank上的优化器上的,即其在param_buffer中的位置信息,因此我们利用这个信息,去获取每个param在当前rank上的切片信息(注意这里是opitimizer要更新的参数的切片信息,而不是对model的param做了切分,实际是复制了一份,可见后文介绍),即flattened_range。
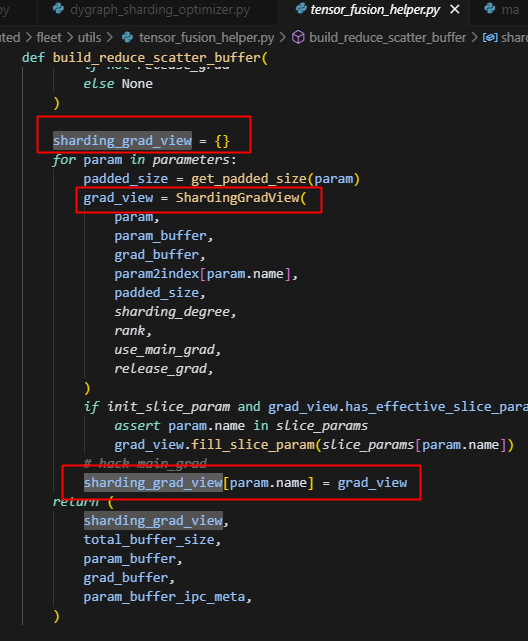
2.build_reduce_scatter_buffer
param_buffer的含义:
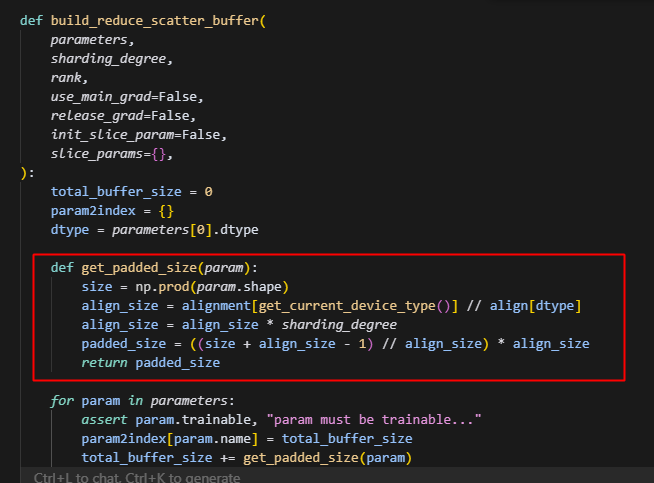
这里首先用get_padded_size函数其实是和V1中差不多的功能,即获取param经过padding之后的大小,不过注意这里的align_size会乘以sharding_degree是为了后续参数可以均分到sharding_group中的每个rank上,这也是和V1最大的区别,V1中的FusedCommBuffer只处理当前sharding_rank对应的参数,而V2是会处理所有参数。
这里的padded_size右边大括号看着跟V1不一样,其实就是一个向上取整公式,当size整除align_size时,无需向上取证,(align_size-1)//align_size=0;而当size不整除时,余数+(align_size-1)//align_size=1,实现向上取整。
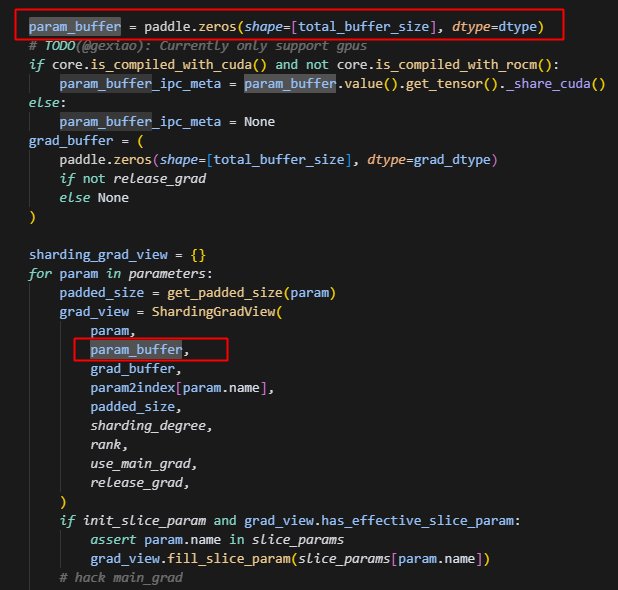
param_buffer即根据当前group所有的param创建的0矩阵,后续当前group所有的param都会以展平后的一维形状放在这个连续的内存空间上,同时与之对应的还有一个grad_buffer,概念是一致的,只不过一个存储的是param,另一个存储的是param对应的grad。而实际的分片逻辑,其实主要在ShardingGradView中,因此我们重点来看一下ShardingGradView。
3.ShardingGradView
这里先针对代码,详细介绍一下param在V2中做sharding的一个过程,后续会在图中讲解,因为整个核心逻辑实际就在ShardingGradView中,因此我们详细解读这个类。
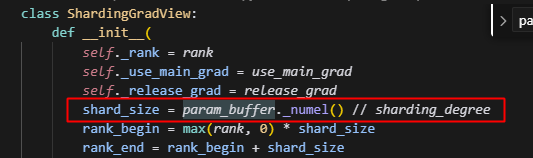
这里的会根据整个param_buffer的大小,去分片,得到每个sharding_rank需要存储的param的大小
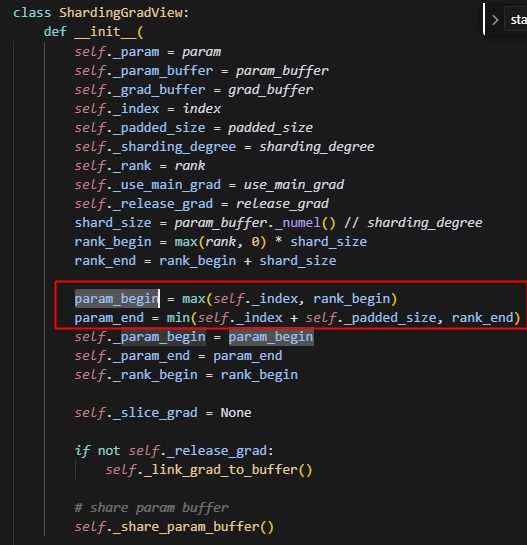
注意这里的param_begin会取param展平之后一维向量的起点位置index和当前rank的起点位置的最大值,所以可以注意到param_begin是会超过rank_end的。
而param_end,则会在经过padding后的param的结尾位置和rank_end中取最小值,因此param_end最大也不会超过rank_end,因此可以用param_begin和param_end的大小关系来判断当前的param是否属于当前的sharding_rank。

_get_padding函数主要是获取slice_param对应grad的padding部分(为了后续做padding_check——因为padding部分是要保证一直是全0,如果有非0元素,说明计算有问题)。因为_param_numel是不包含padding部分的,因此这里通过param的信息,获取了padding的长度,而_slice_param是包含padding的,所以用_slice_grad_numel的大小减去padding的长度就能获取其开始padding 的位置,最后截取padding的那部分数据。 _slice_grad_from_buffr函数是获取grad_buffer上,当前param的grad对应的片段,同时设置slice_grad。可以看到,self._slice_grad在初始化的时候,用的self.、_param_begin, self.、_param_end这一段,而这是经过了padding的大小(与slice_param对应),而返回的tem_grad其实对应了grad未padding的大小与param对应。 self._grad_buffer和self._param_buffer都是用paddle.zeros创建的全0矩阵,大小为当前param组所有param经过padded之后的大小的和。 _link_grad_to_buffer函数是将grad_buffer上当前param的grad片段赋值给self.param.grad,如果�有main_grad就赋值给main_grad,这里是浅拷贝,所以就和grad_buffer共享内存了。(这个操作主要是如果没有开启relese_grad时,才会调用,因为没有relese_grad,则上面讲到过,每次更新grad,其实就是会同步grad_buffer,就间接更新了param.grad)
这里有一个逻辑图,如下所示:
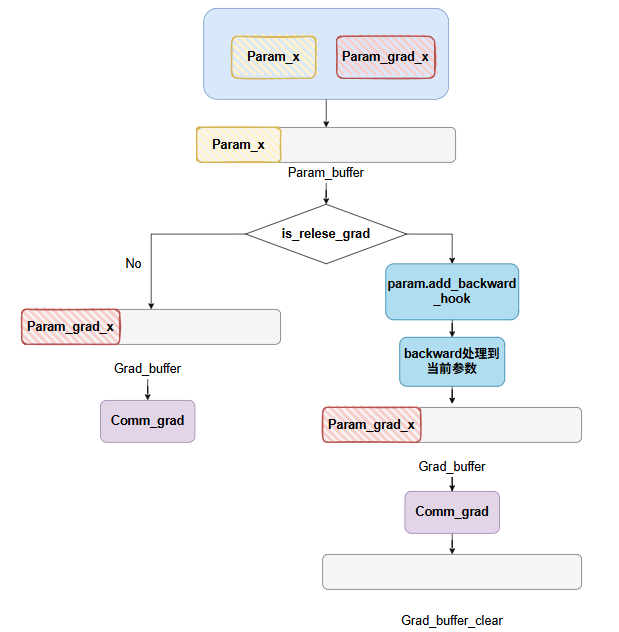
如果设置了relese_grad,则其实在设置每个param的ShardingGradView时,并不会立刻将param.grad映射到grad_buffer的内存上取,而是在backward阶段,处理到该参数时,触发hook,将其grad映射到grad_buffer内存上,再做通信,并且通信结束后,会清除grad。

_share_param_buffer和fill_slice_param两个函数就是最主要的,他们都是做内存映射。
为什么有这里有两个内存映射?
前者是为了将当前的param映射到连续内存的param_buffer上,会使用_share_buffer_to操作,而该操作(我看了一下底层C++的实现),会让param原来的内存引用技术减1,如果引用计数为0,则释放掉了原来的param内存。整个操作即,先将param进行flatten操作,紧接着将其值和属性进行赋值操作,最后让param指向原地址的指针,现在指向param_buffer,实现内存释放和内存共享。(注意这里的param是未经过padding的,且所有的param都会被放到param_buffer上,不仅仅是当前sharding_rank需要处理的参数。)
而后��者是针对slice_param = EagerParamBase(shape=[1], dtype=param.dtype) 使用做内存映射。slice_param在最开始的时候是未初始化的,会根据_param_begin和_param_end来截取param_buffer的片段,得到slice_buffer,紧接着slice_buffer会调用_share_buffer_to操作,和slice_param共享内存,而slice_param就会根据当前的rank的sharidng区间,来截断此时的param。注意这里直接用的param_begin,param_end,所以是会把padding部分也截取下来。
对应的self.param.main_grad和slice_param.main_grad也是上述区别。
之前的一个疑惑点:为什么已经把param映射到了param_buffer上,还要创建slice_param?不直接用param

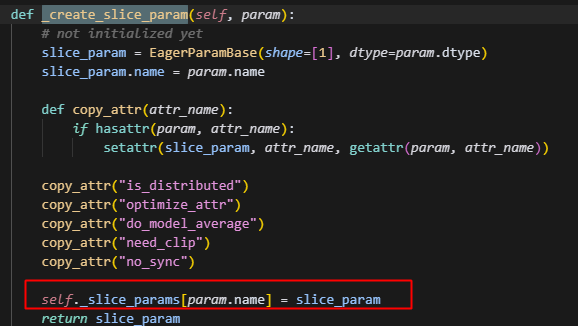
其实就是为了对一个param_buffer上面的参数,做一个sharding的划分,并用slice_param表示划分后的参数,相当于建立一个sharding_view的视角的param。用于后续参数更新当中的实际计算,注意slice_param在分片时,参考的是param经过padding后的大小,注意,此时slice_param和param此时都指向的是param_buffer这片区间,因此后续更新后,对应部分的param数据也会同步更新。


并且由上图代码可以看到,只有has_effective_slice_param为True,即属于当前rank的optimizer的slice_param才会被填充,并用于后续的参数更新。

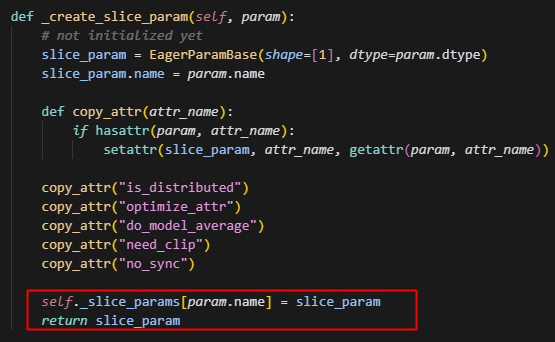
所有slice_param映射完成后,optimizer的参数列表被更新,且只有当前rank上需要处理的参数才会被填充,其余的slice_param都处于未初始化的状态。
并且一个非常重要的点,通过上述操作后,所有param的shape都变成一维了,即每一个slice_params此时都是展平的状态
以下是opitmizer中的param在每个rank上的划分的一个详解图:
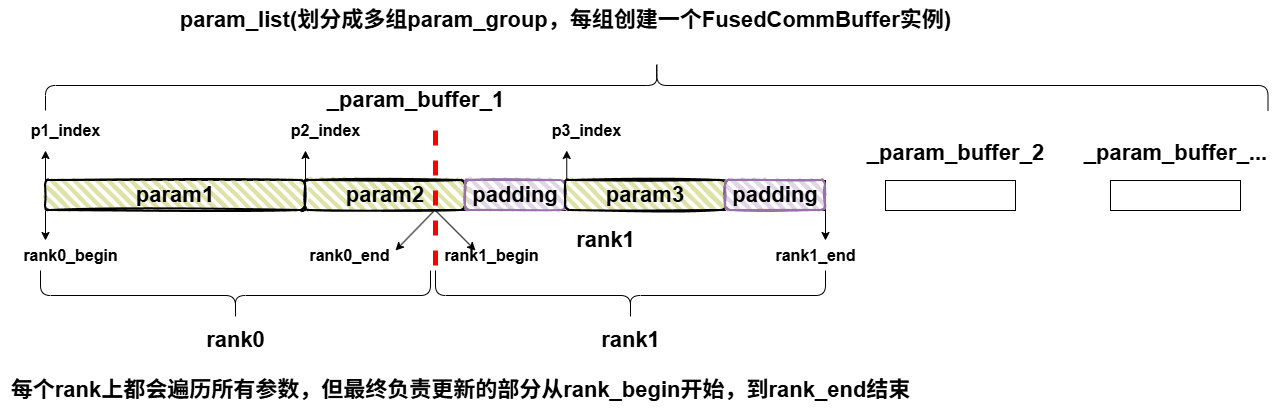
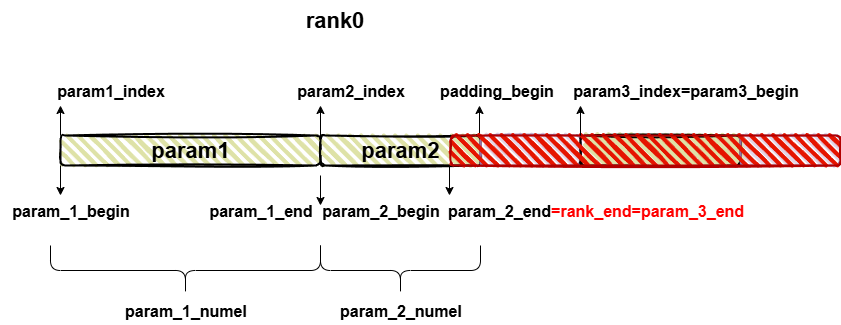
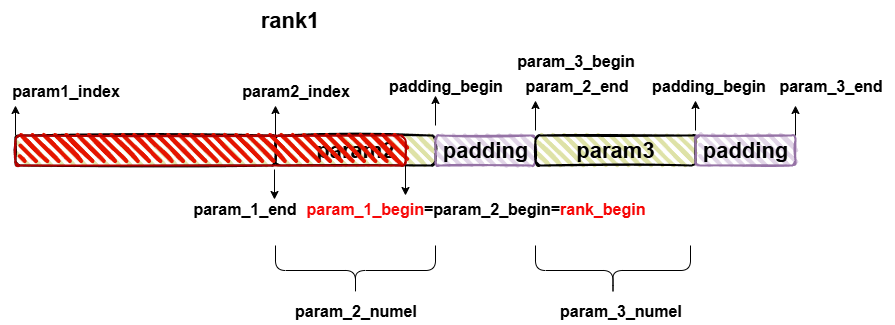
可以看到,只要是不属于当前rank的切片,要么(1) param_begin > param_end;(2) param_end-index < 0。则slice的star,end都取param_begin-index,做空切片,从而控制param_slice_info只保留自己rank上的param的有效切片信息。
注意一个问题,由于param只在边界被切分,因此其实很多param可能只出现在两个相邻的sharding_rank之间
4.其它重要函数
清除对应color的缓冲区
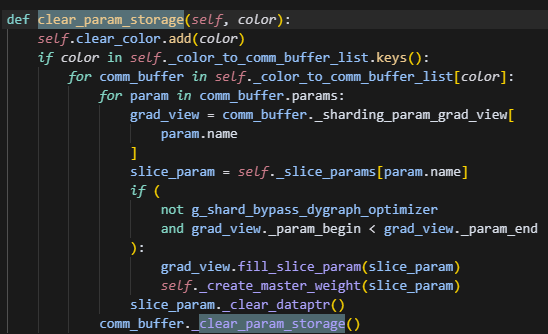

仅在ernie的fp8_quant中用到,该操作将会回收对应color组中的参数分配的param和param_buffer的内存。
参数同步
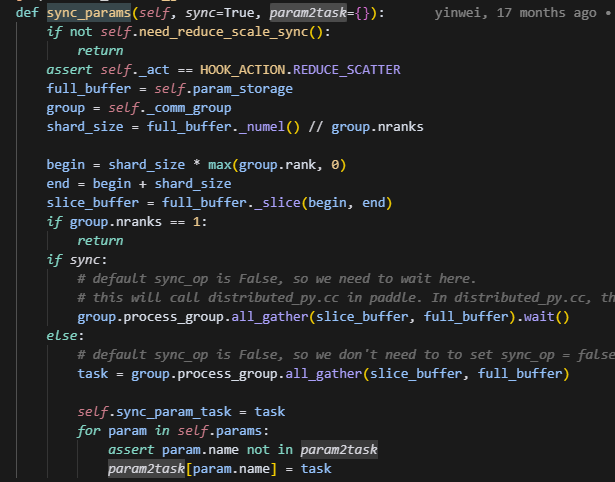
这里参数同步调用了buffer里的sync_params,使用的是all_gather通信,这也非常符合V2的特征,因为每个rank上,拿到的是整个group中的params的切片,所以可以直接使用ring算法,在rank间循环传递切片。
两种_all_gather_overlap_forward方法
方法1:(看代码逻辑不会再执行到这里,存在历史代码遗留问题)
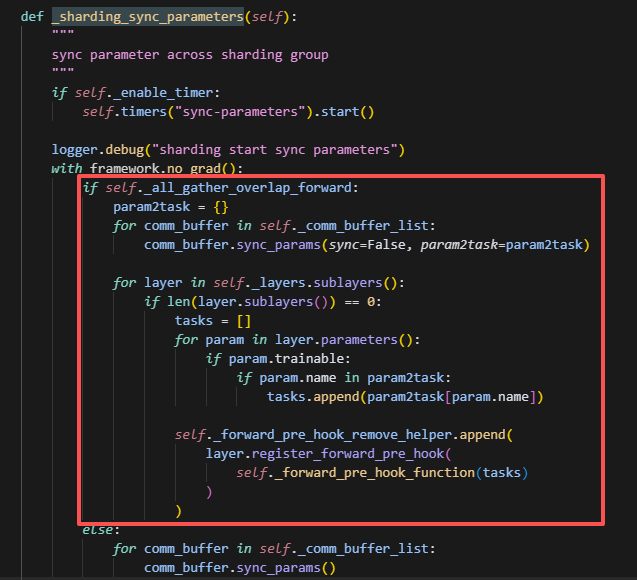
这里的通信与计算overlap的逻辑是:一次性调用所有comm_buffer_list启动通信,而每个叶子节点的layers只需要等待自己需要的那部分param更新完成,即可做forward,无需等待其它的通信。
方法2:当前执行的逻辑
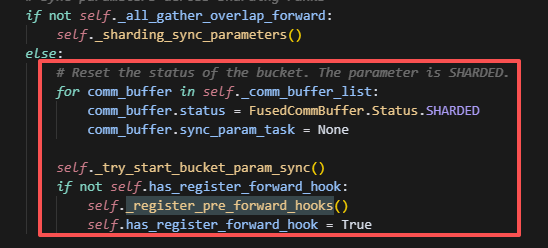
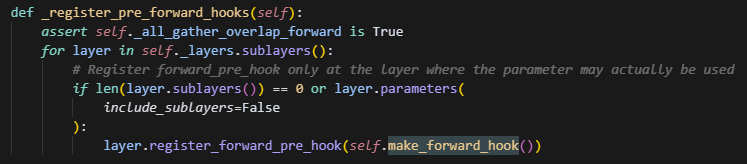
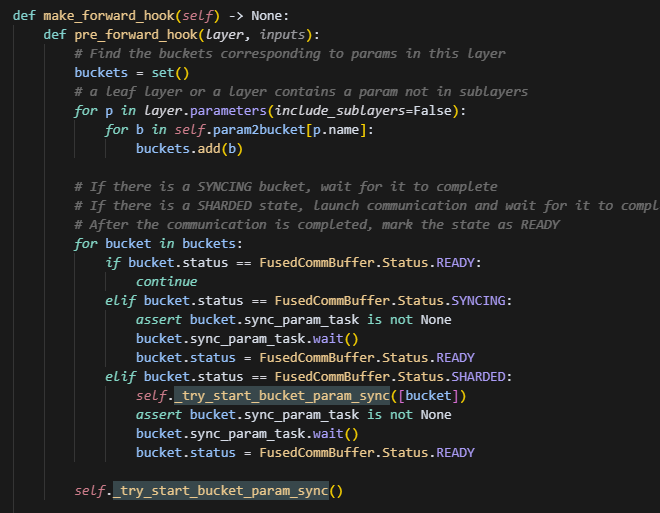
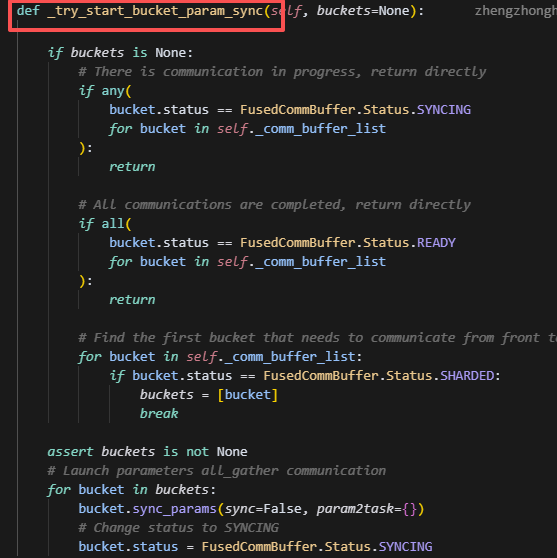
现在执行的逻辑,细粒度更高,会给每个buffer设置status状态,分为syncing、ready、shared,分别表示正在同步,同步结束和需要同步。一开始所有buffer都是sharded状态,并且会用第一个buffer作为启动项(这个操作猜测大概是建立通信上下文,做通信初始化,避免第一次通信时间长而造成的长等待),接着会给所有的叶子节点layer创建hook,而这个hook的主要操作是取出当前layer需要的param,找到这些param对应的buffer,发起一次通信,并等待。因此是以一个layer需要的param数,决定一次发起通信的数据量有多少。
对比两个方法
前者一次性发起全部通信,通信与计算完全重叠,没有bubble空间,时间较快,但是显存峰值较大,适合小批量训练。
后者一次按需发起通信,即每次通信量有当前layer涉及到的参数决定,存在bubble,时间相对较慢,但是显存峰值大大降低,适合大规模的训练。
一点代码问题:
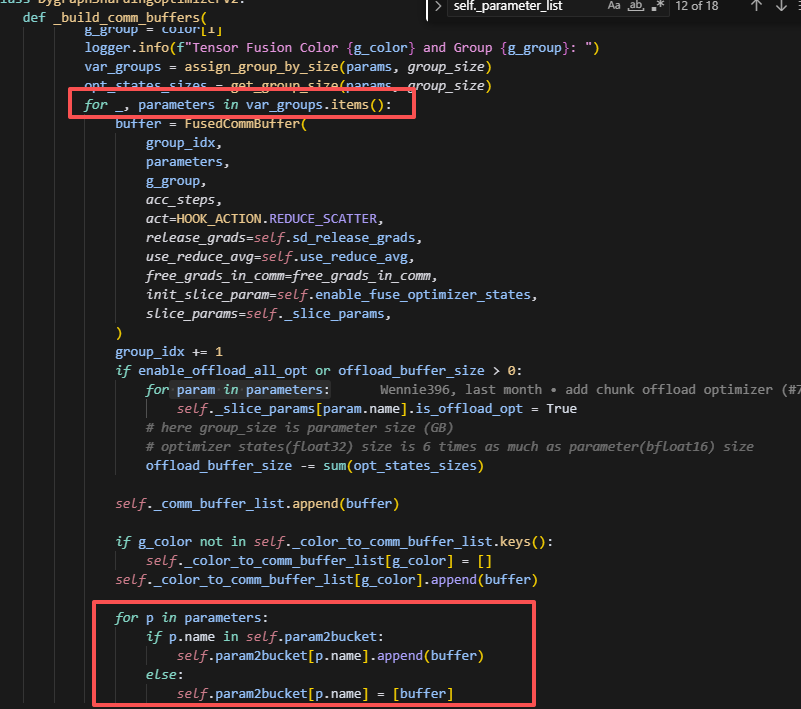
我觉得这里根本不会出现p.name in self.param2bucket的现象,不知道为什么这么设计。这里感觉完全不需要用bucket,就用param2buffer就行,因为单个rank上一定不会出现同一个param有多个buffer。