VPP优化工作
1.优化vpp编排
1. pp_degree==acc_steps��的vpp编排优化
当前的vpp编排思想,针对pp_degree与acc_steps二者相等时,采用的是直接将编排模式设置为了FthenB的编排,该方法并不能达到vpp编排思想的降低设备的显存峰值,实际在设备中的编排效果如下图所示,此时pp_degree=acc_steps=4,num_chunks=2,hidden_layer=8

代码优化后的图如下,可以看到,我们能和vpp编排思想保持一致,成功降低设备的峰值显存

2. acc_steps%pp_degree !=0 时vpp编排支持
当前的vpp编排思想,不支持非均衡vpp的编排,即,只有当acc_steps为pp_degree的整数倍时,才能实现编排,因此我对代码做了改进,改进后,只需要保证acc_steps>=pp_degree即可,现在能支持非均衡vpp的编排,编排效果图如下,此时pp_degree=4,acc_steps=5,num_chunks=2,hidden_layer=8

工作具体相关文档:vpp非均匀切分任务
2.支持VPP去尾操作
- 当前的vpp编排仅仅支持模型hidden_layer层数整除vpp_degree的情况,然而在很多时候,模型hidden_layer的最后一层的计算量和计算时间往往都要大于前面的层,因此为了满足一定精度的同时拥有更快的训练速度,往往可以将hidden_layer的最后一层给去掉,不会给模型带来较大的精度影响,尤其是模型很大的时候,同时也能使训练速度有一个较高的提升,因此支持vpp去尾操作具有价值较大的现实意义。
- 这里我将展示一个在
llama模型上测试的效果,此时我设定的pp_degree=4,vpp_degree=2,acc_step=4: 当hidden_layer=8时,vpp编排的结果如下: 当hidden_layer=7时,vpp编排的结果如下:
当hidden_layer=7时,vpp编排的结果如下:
 因为vpp编排是根据chunk进行编排的,所以在两个参数下,编排的效果是一致的,这也证明了代码的准确性和通用性
因为vpp编排是根据chunk进行编排的,所以在两个参数下,编排的效果是一致的,这也证明了代码的准确性和通用性 - 同时我们观察一下训练10个step后的结果:
当hidden_layer=8时,训练后的结果如下:
 当hidden_layer=8时,训练后的结果如下:
当hidden_layer=8时,训练后的结果如下:
 可以看到,此时loss相差0.007,但是时间上相差了0.005*10=0.05s。而这仅仅是训练的step为10,并且hidden_layer较小时的结果,可以预期,当模型较大,训练步数较大时,带来的时间收益是非常显著的。
可以看到,此时loss相差0.007,但是时间上相差了0.005*10=0.05s。而这仅仅是训练的step为10,并且hidden_layer较小时的结果,可以预期,当模型较大,训练步数较大时,带来的时间收益是非常显著的。
工作具体相关文档:Vpp去尾工作
3支持非均衡VPP编排的灵活模型层分配策略
- 当前自动并行下非均衡vpp编排无法支持用户灵活进行模型层分配,即在任意设备上分配任意模型层数,当前仅支持,在每个设备上每个chunk中放入相同的模型层数。
- 以下举一个例子验证当前在任意设备分配任意模型层数存在的问题:
这里选择hidden_layer=8,layer_to_mesh=[mesh0,mesh0,mesh0,mesh0,mesh0,mesh1,mesh1,mesh1](即0设备5层,1设备3层)
,运行发现,vpp编排能正常进行,但是编排方式是假灵活分配,如下图所示:

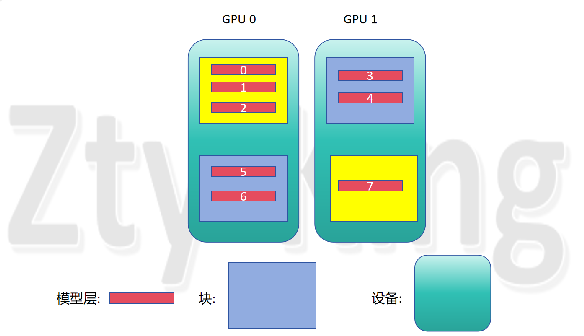
 可以看到此时在第0,1,2层hidden_layer分配在0号设备,第3,4层分配在1号设备,第5,6层分配在0号设备,第7层分配在1号设备,与用户的layer_to_mesh(即0设备5层,1设备3层),保持一致。
可以看到此时在第0,1,2层hidden_layer分配在0号设备,第3,4层分配在1号设备,第5,6层分配在0号设备,第7层分配在1号设备,与用户的layer_to_mesh(即0设备5层,1设备3层),保持一致。 - 方法简述:
- 首先过滤掉op.dist_attr为None的ops,因为在后续调用get_pp_stage_by_process_mesh函数获取当前模型层的pp_stage时需要用到op.dist_attr.process_mesh。
- 在同一个layer上的op对应的pp_stage是相同的,因此用struct_name区分不同层的op,并且每层只需要利用一个op来计算对应的pp_stage。
- 确保每个设备的分配的layer数大于等于chunk数,即保证每个chunk中至少包含一个layer。
- 设备内使用Round-Robin算法,对每个设备来说:设备中每个块轮循增加layer数,直到达到当前设备的指定数
- 最终得到按用户意图分配来编排的结果
工作具体相关文档:进阶——基于VPP编排的灵活模型层分配策略研发