Transformer架构知识
1.Transformer三类架构
Transformer架构分为三类:编码器(Encoder-only)、解码器(Decoder-only)、编码器-解码器(Encoder-Decoder-only)
1.Encoder-only模型
这些模型通常用于理解任务、文本分类、命名实体识别等
特点是每个token都能那个看到整个序列(双向注意力)
代表模型:BERT、RoBERTa、DistilBERT等
个人理解:对于像文本做embedding和上述提到的整个文本句子分类,�这些都比较关注整个语句的特征,但并不在意处理这个文本的每个token的顺序,因此优点在于可以提取出全局双向的文本特征,以及可以并行处理每一个token。
2.Decoder-only模型
这些模型一般用于生成任务、文本生成等
因为decoder模块使用的是mask_multi_self_attention,而其特点就是,在预测下一个token之前,只知道前面token的信息,以自回归的方式工作,根据输入的整个序列生成一个token,然后添加到输入序列中,再生成下一个token。
代表模型:GPT、ChatGLM、LLaMA、Bloom
个人理解:这类模型主要做的任务特点是,文本的token是在意其token顺序的,并且每次处理token,需要依赖前一次的状态,有点类似于LSTM这类时序模型。
3.Encoder-Decoder模型
这类模型通常用到 Seq2Seq,如机器翻译、文本摘要
Encoder部分处理输入序列,Decoder部分以自回归的方式输出序列。同时Decoder还会使用交叉注意力(Cross-Attention)来使用编码器的输出。
代表模型:T5、BART、M2M-100等
个人理解: 专注于文生文,既要完整提取输入文本的全部特征,又要以自回归的方式生成一段相关的文本。所以既利用了输入文本的主要特征,又结合输入文本+已预测token的特征,来预测最终的输出。
2.Transformer(Encoder-Decoder基本框架)
Transformer框架主要由四部分模块组成,分别为输入模块,输出模块,Encoder模块以及Decoder模块。
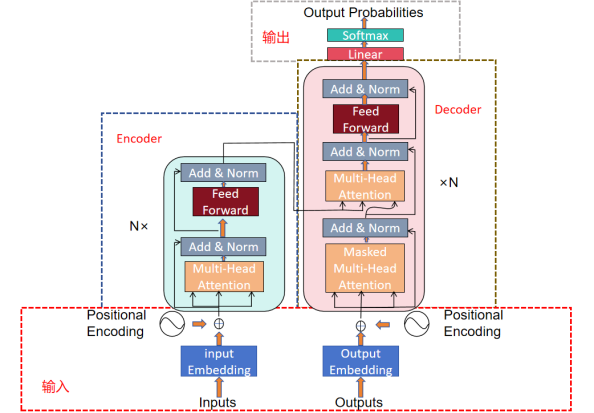
1.输入模块
Transformer中的输入矩阵Xn×d是由每个词Embedding和位置Embedding相加得到的,如图所示,其中矩阵x的行数n表示句子中的单词数(也称为序列长度,这里假设batch_size为1),列数d表示向量的维度(在原论文中,d=512),Encoder模块的输入为source数据即原数据,Decoder模块的输入为target数据即目标转换数据,target数据只有在监督训练时才会使用,进行预测时则不会接收。
其中词Embedding可以采用Word2Vec等单词转向量的算法预训练得到,或者也可以在Transformer中训练获得;而之所以要再加上位置Embedding,最主要的原因是Transformer不适用RNN的结构,因此它不再能利用单词的顺序信息,而这部分信息对于模型的理解和预测来说十分重要,因此Transformer使用位置Embedding来保存单词在文本中的相对或绝对位置。位置Embedding通常用PE(Position Embedding)表示,PE也可以通过训练得到,而在Transformer的模型中,作者采用了计算公式获取:
![]()
![]()
其中pos表示单词在句子中的位置,即pos=0,1,2...,例如“我是人”中的人,pos=2,d则表示PE的维度,和词Embedding对应的维度保持一致,2i表示偶数的维度,2i+1表示奇数的维度。采用公式获取PE的主要原因是,当使用模型处理一个新的句子时,此时的句子比训练集中所有句子都要长,这时就可以用公式计算得到较长部分的Embedding,同时使用公式计算,也可以让模型更容易算出相对位置,因为假定两个词a,b的间距长度为q,a的位置为pos,则b相对于a的位置就为PE(pos+q),而又因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B),因此可以推导出b相对于a的PE。
序列中每个 token 的 位置索引pos = 0, 1, ..., L-1,维度索引 i=(0,1,...,dmodel−1)//2(用于计算每个维度上的 PE,除以2,是为了让每两对的sin cos的频率一致,则可以用上面提到的三角函数恒等式做相对位置的计算。)
2.Encoder模块

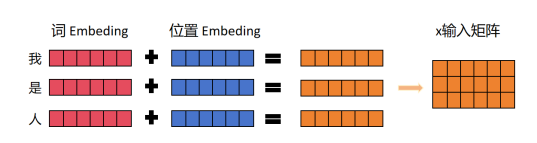
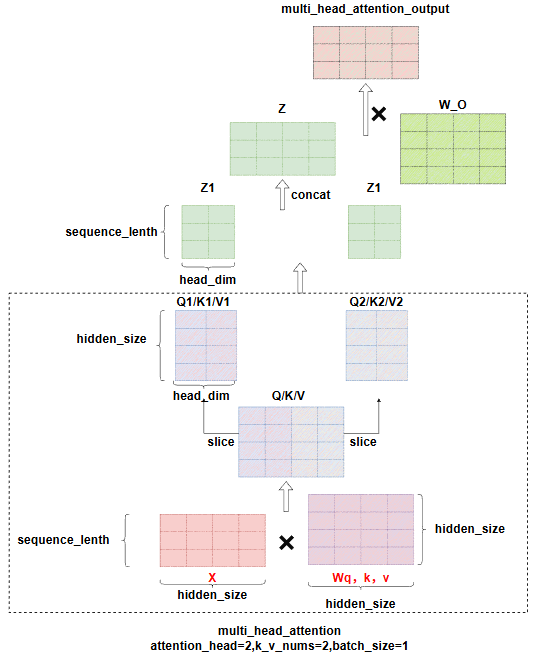
Transformer的Encoder模块主要由多个Encoder堆叠而成,每个Encoder中包含Multi-Head Attention、Add&Norm、Feed-Forward部分,,其中最重要的就是Multi-Head Attention部分,该部分是由多个Self-Attention组成的,因此本节重点介绍一下Self-Attention的结构,如图1.3即为Self-Attention的结构图。其中Q(查询),K(键值),V(值)这三个值即为Self-Attention模块的输入值,这些输入值是输入的矩阵X(或者是上一个Encoder模块的输出)乘以相应权重进行线性变化得到的,如图即为Qn×m的一个计算过程,其中Qn×m的行数n表示单词数,而列数m列表示向量的维度,K和V也按此方法计算,在模型训练时,WQ,WK,WV中的数值会随着训练而变化。

计算得到Q,K,V后,即可通过公式计算得到self-Attention的输出:

其中dk是Q,K矩阵的列数,即向量维度,此步操作是为了防止Q和KT的内积过大,得到一个n×n的矩阵如图所示,该矩阵可表示单词之间的attention强度。
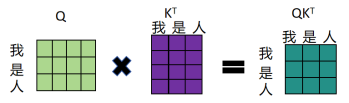
再使用Softmax对每一行数进行归一化处理,最后乘上V得到最终的输出Z,例如Z的第一行Z1是由所有单词的V值(每个单词对应一行V值)乘以attention系数的比例再求和计算得到的,如图所示。
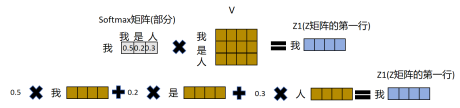
由于Multi-Head Attention是由多个Self-Attention模块组合而成的如图所示,多个Self-Attention的输出Zi,按列拼接在一起,再进行线性变换得到最终输出矩阵Z,矩阵Z的维度和输入矩阵X的维度相同。
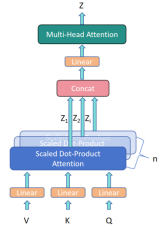
如下图所示,在实际计算时,W_Q、W_K、W_V的最后一个维度,将根据attention_head_nums,划分成hidden_size//attention_head_nums的大小,输入X分别和这些Q,K,V做注意力计算,得到Zi,最终Zi拼接回和X一样的维度,再经过矩阵W_O,对每个注意力头获取的特征做聚合,得到最终的多头注意力的输出。此时的输��出的大小和输入X是相同的,而Zi的最后一维,大小为head_dim,head_dim通常等于hidden_size/head_nums。
Add&Norm层由Add和Norm两部分组成,如对应公式所示,Add是一种残差连接操作,多用于Res-Net卷积神经网络,可以优化深层网络的梯度消失现象,而Norm则指Layer Normalization,用于保证每一层的神经元输入的均方差一致,这样做的目的是加快收敛。X+SubLayer(X)属于Add的残差连接操作,而LayerNoerm属于Norm操作,进行归一化。
![]()
![]()
插播一条,Layer Normalization和Batch Normalization的区别:一句话总结,batch normalization是针对一组数据,如一个min batch的数据之间的每一个channel上做归一化操作,而Layer Normalization则是针对单个token的最后一维,也就是特征维度做归一化。
FeedForward层则是一个两层的全连接层,第一层的激活函数为Relu,第二层则不用激活函数,公式所示:
![]()
3.Decoder模块
Transformer的Decoder模块主要由多个Decoder堆叠而成,每Decoder中包��含Masked Multi-Head Attention、Multi-Head Attention、Add&Norm、Feed-Forward部分,与Encoder模块最主要的不同在于Masked Multi-Head Attention部分,因此本小节重点说明Masked Multi-Head Attention部分,与Multi-Head Attention中的Self-Attention一样,也需要通过输入矩阵X,此时的输入矩阵X为训练时对应target数据X经过词Embedding和位置Embedding,并相加后得到,根据X计算得到矩阵Q,K,V,并计算得到QKT,此时,需要将矩阵QKT与Mask矩阵相乘,用于遮挡住每一个单词之后的信息,如图所示,即在训练时,因为会将整个target数据传入Decoder,此时为了防止“作弊”,即使用Mask操作,使得模型在预测当前单词时,只能使用该单词之前的信息。
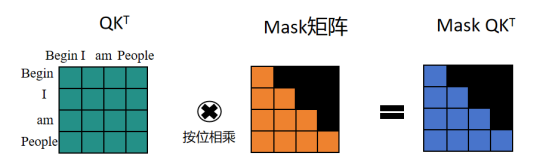
通过上述操作得到Mask QKT与矩阵V相乘后,得到输入Zi,同样拼接多个输入Zi后,线性变换得到Masked Multi-Head Attention的输出Z,经过Add&Norm模块处理后,与矩阵WQ相乘得到矩阵Q,同时将来自于Encoder的输出Z,与矩阵WK,WV相乘得到矩阵K,V,作为Multi-Head Attention的输入,Decoder模块的Multi-Head Attention部分除了输入与Encoder模块不同,其它均相同。
Mask self-attention的作用:
必须明确,只在训练阶段有用,推理阶段无用,训练阶段可以把一整个矩阵输入进去,如下图所示,则可以得到,当前模型分别接收到第1~n个token后的预测结果,第一行就表示只包含第一个token信息,此时是预测第二个token时的概率分布。
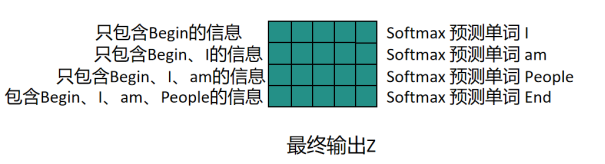
训练计算损失步骤如下:
![]()
首先每一行可以得到一个此时预测下一步token的logits,并且我们有一个当前的目标token的标签,即one-hot向量yt,这个向量是只有在目标token的token_id的位置上为1,其它都是0,则将其输入给Cross-Entropy会做如下操作:
![]()


先做一个soft_max将logits转化成概率分布,由于只有位置t的数值是1,所以其实:
![]()
这里实际计算的就是取模型对真实token的预测概率取负对数,由于概率是0-1之间,概率越大,模型预测约准确,则CEt越小,最后的Loss是取整个序列的平均交叉熵的值:

4.输出模块
Transformer的输出模块由一层线性变化层和Softmax层组成,Linear层主要是将特征维度映射到词表大小即VocabularySize,而Softmax层会将Linear层输出的数据归一化,转换成0-1之间的概率,再根据解码策略选出对应的token_id,最后根据tokenizer解析出该token对应的单词。
5.常见问题
1.为什么要除以根号(dk)?
因为我们假设Q,K的元素都是均值为0,方差为1的随机变量,它们点积后:

根据统计学原理,结果的方差变成了dk,如果dk很大,那么其实表示点积的结果范围很大,也就是点积中包含很大的数,而这时候如果不缩放,输入softmax的值很大,而softmax的特性,当输入差异很大时,输出的某些元素会及其接近0或1,形成one-hot的数据,而这些极端位置的梯度几乎为0,在backward的时候梯度传递到这里就变成0,导致所有权重无法更新了。
2.为什么用Layernorm而不用Batchnorm
核心区别在于统计的维度不同,BN是在批次维度上做归一化,依赖于样本间的统计量,而LN是在特征维度上做归一化,只依赖于当前样本自身。
(1) NLP输入句子是变长序列
对于BN来说,面对不同长度的序列,需要对短句子padding,计算出的统计量是无效或者说会产生偏差
对LN来说,对每个Token自身的特征向量做归一化,完全不依赖序列长度,天然适合变长输入
(2) Batch Size限制
Transformer模型很大,显存有限,往往会用较小的Batch训练,而BN在batch很小的情况下,容易导致均值方差噪声很大,导致模型训练不稳定
而LN计算与Batch size无关,哪怕只有一个数据也能工作。
(3) 训练推理的一致性
BN的硬伤:训练时使用当前Batch的统计量,推理时使用"滑动平均"的全局统计量,若在NLP用,会导致训练推理表现不一致。
而LN则训练推理完全用一样的逻辑,天然适合。
3.layernorm是在self attention之前还是之后,为什么?
1.Post-LN(放在后面):传统的像Bert,transformer基础模型,都是用的是Post-LN,即先做attention计算,然后做残差连接,最后将输出给�到layernorm处理,这样做会导致模型网络层较深的时候,梯度在回传过程中逐渐被削弱,导致最后梯度消失了
2.Pre-LN(放在前面):而现在主流的GPT,LLAM等模型,都是Pre-LN,即只有要进入attention时做layernorm,而残差连接,即将完整X加到attention处理后的数据,这部分操作的完整X,是不经过layernorm处理的,这样输入X就可以经过很多层传递仍然保持原来的信息,当然为了不让最终输出的数据数值爆炸,通常会在最后的输出层加一个layernorm做一次归一化操作。