Native Sparse Attention
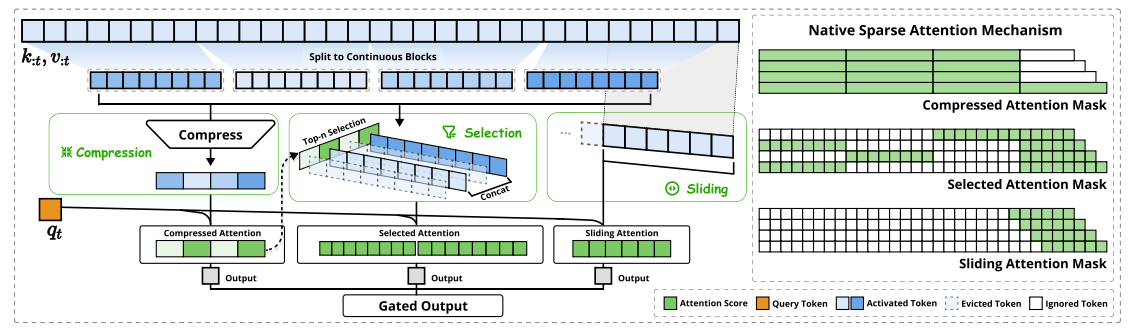
Native Sparse Attention分为:
1. 粗粒度压缩注意力 (Compressed Attention): 处理粗粒度的模式,通过压缩 Token 块来捕获全局信息。
2. 选择注意力 (Selected Attention): 处理重要的 Token 块,选择性地保留细粒度的信息。
3. 滑动窗口注意力 (Sliding Window Attention): 处理局部上下文信息。
1.粗粒度压缩注意力
以下是粗粒度压缩注意力的公式:
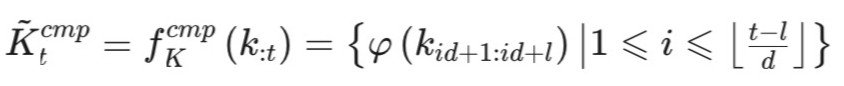
从整个图和这个公式可以看到,粗粒度压缩的操作,主要是通过对当前的K,V矩阵的大小进行压缩,其中t表示当前token属于第t步,我们要处理的也就是t步之前所有的token。首先将这些token按照chunk_size做一个分块处理,紧接着会进行压缩,压缩通常采用pooling,平均池化或者最大池化,也可以用一个MLP层来压缩维度等等操作。这样就将原来的t个token给压缩到了个,其中l表示chunk_size,d表示块之间的步长,也就是块中间是可以重叠采样的。
然后使用当前Q与压缩后的K,V做计算,因为是在seq_len维度做的压缩,所以不影响attention的计算,计算后仍然是(seq_len,hidden_dim)。这样就得到了第一部分的粗粒度压缩注意力。
2.选择注意力
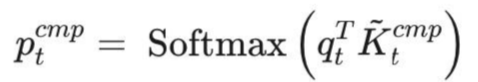

选择注意力其实会基于粗粒度压缩注意力来金松计算,首先由粗粒度压缩操作我们得到了压缩后的K,V,并可以得到一个Compressed Attention分数矩阵,我们选择top-n个较大的块,然后取出这些块实际的token序列,即把一个块展开回chunk_size大小的原始token,然后concat起来,再和Q矩阵做注意力计算,这样就得到了选择注意力的输出。
3.滑动窗口注意力
![]()
基于滑动窗口的大小,选择[t-w:t]个token的K,V信息,并和Q矩阵做注意力计算,得到滑动窗口注意力的结果。
4.Gate Network
这里会有一个门控网络,是可训练的,分别汇总粗粒度压缩注意力、选择注意力、滑动窗口注意力,相当于会对三个结果进行加权平均。
5.总结
粗粒度压缩注意力相当于对整个全局信息进行摘要,总结出一些重要的信息点,从而压缩全局信息量,而选择注意力则是从这个全局摘要中,进一步去关注那些比较重要的信息,而滑动窗口注意力则是通过保留上下文信息,从而让当前token的预测是依赖于了上下文的信息和文本顺序的,进一步保证attention结果的准确性。
6.硬件对齐系统
为了在训练和预填充期间实现FlashAttention级别的加速,论文在Triton上实现了硬件对齐的稀疏注意力内核。优化了块状稀疏注意力以利用Tensor Core 和 内存访问,确保平衡算术强度。具体来说有以下优化:
**1.块状内存访问模式:**通过合并加载,最大化Tensor Core利用率,减少冗余的KV传输。
**2.循环调度:**在内核中巧妙地安排循环,消除冗余地KV传��输
**3.组中心数据加载:**对于每个内部循环,加载同一组内地所有查询及其共享的稀疏键/值块索引。
**4.共享KV获取:**在内部循环中,顺序加载连续的K/V块到SRAM中,以最小化内存加载。
**5.网格调度的外循环:**由于内部循环长度在不同查询块之间几乎相同,将查询/输出循环放在Triton的网格调度器中,以简化和优化内核。
如图即为NSA的内核设计。
DSA(Deepseek Sparse Attention)
NSA是根据压缩注意力筛选block-wise KV,而DSA则通过索引Indexer网络筛选出element-wise KV。细粒度更小。
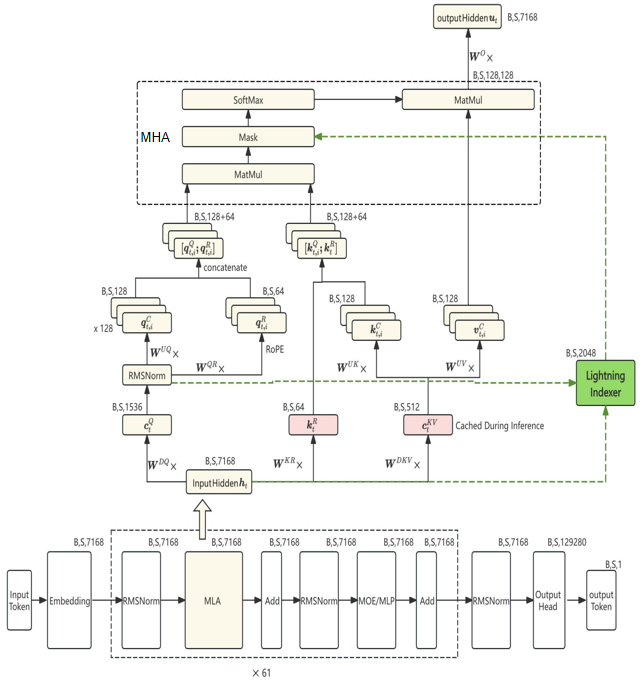
DSA其实是在MLA(上图为prefill阶段的MLA)的基础上增加了一个Lightning Indexer(闪电检索器),用来挑选一些比较重要的token 做attention计算。
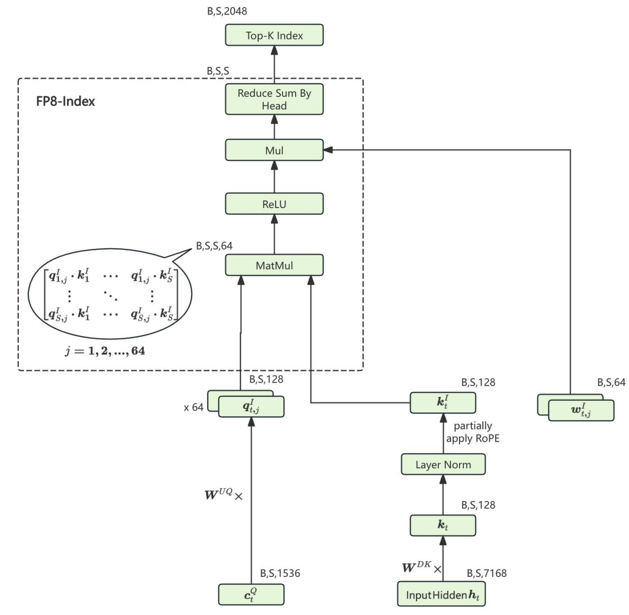

![]()
如图为Lightning Indexer的核心逻辑,输入是Q的降维矩阵和上一层的输入,首先会和K的降维矩阵相乘,并且做RoPE处理得到,而则会和升维矩阵相乘得到,而因为Lightning Indexer也采用多头的机制,因此整个Q会被划分成多个q,这里采用MQA的思想做qk的计算,得到每个头的qk矩阵,并且每个头都有一个权重矩阵,最后对每个头做reduce,即求和操作,得到所有token对历史token的注意力权重矩阵,并且选出top-k个token,这里的操作就是构建一个mask矩阵, 未被选中的token均设定为0即可。后续key-value对只计算未被mask的那些数据。
这里说明一点,并不是矩阵被设置为0元素,整个矩阵计算量就能直接减小,而是通过设置为0元素,对于这些0元素的位置,就不做矩阵元素的计算,从而减少计算量。在CUDA中,是以块为单位,判断整块计算元素是否做计算,而不是单独一个元素判断。
图中的头数有64个,所以是64个(B,S,128)q与1个(B,S,128)k做计算,采用广播的形式,每个q都得到一份k的副本,最后得到64个(B,S,S)的attention权重,所以也就是为什么最后维度是(B,S,S,64),这里不做softmax,直接做relu,进而再用w对每个头做加权,然后做reduce得到输出(B,S,S),这里top-k,k设置的2048,所以从中挑选了2048个与每个token相关性较大的token。注意每个token相关的2048个token并不一定一样,因此最终的输出是(B,S,2048)。
官方代码:
class Indexer(torch.nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.dim: int = args.dim
self.n_heads: int = args.index_n_heads
self.n_local_heads = args.index_n_heads // world_size
self.head_dim: int = args.index_head_dim
self.rope_head_dim: int = args.qk_rope_head_dim
self.index_topk: int = args.index_topk
self.q_lora_rank: int = args.q_lora_rank
self.wq_b = Linear(self.q_lora_rank, self.n_heads * self.head_dim)
self.wk = Linear(self.dim, self.head_dim)
self.k_norm = LayerNorm(self.head_dim)
# weights_proj in the checkpoint is stored in bf16, while the parameters here are stored in fp32 for convenient.
self.weights_proj = Linear(self.dim, self.n_heads, dtype=torch.float32)
self.softmax_scale = self.head_dim ** -0.5
self.scale_fmt = args.scale_fmt
self.register_buffer("k_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.head_dim, dtype=torch.float8_e4m3fn), persistent=False)
self.register_buffer("k_scale_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.head_dim // block_size, dtype=torch.float32), persistent=False)
def forward(self, x: torch.Tensor, qr: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
bsz, seqlen, _ = x.size()
end_pos = start_pos + seqlen
q = self.wq_b(qr)
q = q.view(bsz, seqlen, self.n_heads, self.head_dim)
q_pe, q_nope = torch.split(q, [self.rope_head_dim, self.head_dim - self.rope_head_dim], dim=-1)
# rope in indexer is not interleaved
q_pe = apply_rotary_emb(q_pe, freqs_cis, False)
q = torch.cat([q_pe, q_nope], dim=-1)
k = self.wk(x)
k = self.k_norm(k)
k_pe, k_nope = torch.split(k, [self.rope_head_dim, self.head_dim - self.rope_head_dim], dim=-1)
# rope in indexer is not interleaved
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis, False).squeeze(2)
k = torch.cat([k_pe, k_nope], dim=-1)
q = rotate_activation(q)
k = rotate_activation(k)
q_fp8, q_scale = act_quant(q, block_size, self.scale_fmt)
k_fp8, k_scale = act_quant(k, block_size, self.scale_fmt)
self.k_cache[:bsz, start_pos:end_pos] = k_fp8
self.k_scale_cache[:bsz, start_pos:end_pos] = k_scale
weights = self.weights_proj(x.float()) * self.n_heads ** -0.5
weights = weights.unsqueeze(-1) * q_scale * self.softmax_scale
index_score = fp8_index(q_fp8.contiguous(), weights, self.k_cache[:bsz, :end_pos].contiguous(), self.k_scale_cache[:bsz, :end_pos].contiguous())
if mask is not None:
index_score += mask
topk_indices = index_score.topk(min(self.index_topk, end_pos), dim=-1)[1]
topk_indices_ = topk_indices.clone()
dist.broadcast(topk_indices_, src=0)
assert torch.all(topk_indices == topk_indices_), f"{topk_indices=} {topk_indices_=}"
return topk_indices
def weight_dequant(weight, scale):
shape = weight.shape
assert weight.dim() == 2
weight = weight.view(shape[0] // block_size, block_size, shape[1] // block_size, block_size).transpose(1, 2).contiguous().view(-1, block_size * block_size)
weight = (weight.float() * scale.view(-1, 1).float()).to(torch.get_default_dtype()).view(shape[0] // block_size, shape[1] // block_size, block_size, block_size).transpose(1, 2).contiguous().view(shape)
return weight
class MLA(nn.Module):
"""
Multi-Head Latent Attention (MLA) Layer.
Attributes:
dim (int): Dimensionality of the input features.
n_heads (int): Number of attention heads.
n_local_heads (int): Number of local attention heads for distributed systems.
q_lora_rank (int): Rank for low-rank query projection.
kv_lora_rank (int): Rank for low-rank key/value projection.
qk_nope_head_dim (int): Dimensionality of non-positional query/key projections.
qk_rope_head_dim (int): Dimensionality of rotary-positional query/key projections.
qk_head_dim (int): Total dimensionality of query/key projections.
v_head_dim (int): Dimensionality of value projections.
softmax_scale (float): Scaling factor for softmax in attention computation.
"""
def __init__(self, args: ModelArgs):
super().__init__()
self.dim = args.dim
self.n_heads = args.n_heads
self.n_local_heads = args.n_heads // world_size
self.q_lora_rank = args.q_lora_rank
self.kv_lora_rank = args.kv_lora_rank
self.qk_nope_head_dim = args.qk_nope_head_dim
self.qk_rope_head_dim = args.qk_rope_head_dim
self.qk_head_dim = args.qk_nope_head_dim + args.qk_rope_head_dim
self.v_head_dim = args.v_head_dim
self.wq_a = Linear(self.dim, self.q_lora_rank)
self.q_norm = RMSNorm(self.q_lora_rank)
self.wq_b = ColumnParallelLinear(self.q_lora_rank, self.n_heads * self.qk_head_dim)
self.wkv_a = Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim)
self.kv_norm = RMSNorm(self.kv_lora_rank)
self.wkv_b = ColumnParallelLinear(self.kv_lora_rank, self.n_heads * (self.qk_nope_head_dim + self.v_head_dim))
self.wo = RowParallelLinear(self.n_heads * self.v_head_dim, self.dim)
self.softmax_scale = self.qk_head_dim ** -0.5
self.scale_fmt = args.scale_fmt
if args.max_seq_len > args.original_seq_len:
mscale = 0.1 * args.mscale * math.log(args.rope_factor) + 1.0
self.softmax_scale = self.softmax_scale * mscale * mscale
self.indexer = Indexer(args)
self.register_buffer("kv_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.kv_lora_rank), persistent=False)
self.register_buffer("pe_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.qk_rope_head_dim), persistent=False)
self.dequant_wkv_b = None
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
"""
Forward pass for the Multi-Head Latent Attention (MLA) Layer.
Args:
x (torch.Tensor): Input tensor of shape (batch_size, seq_len, dim).
start_pos (int): Starting position in the sequence for caching.
freqs_cis (torch.Tensor): Precomputed complex exponential values for rotary embeddings.
mask (Optional[torch.Tensor]): Mask tensor to exclude certain positions from attention.
Returns:
torch.Tensor: Output tensor with the same shape as the input.
"""
bsz, seqlen, _ = x.size()
end_pos = start_pos + seqlen
qr = self.q_norm(self.wq_a(x))
q = self.wq_b(qr)
q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim)
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
q_pe = apply_rotary_emb(q_pe, freqs_cis)
kv = self.wkv_a(x)
kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
kv = self.kv_norm(kv)
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
# we use fp8 kv cache in actual deployment, so here we simulate the precision by casting kv to fp8 and then back to bf16.
kv_fp8, kv_scale = act_quant(kv, block_size, self.scale_fmt)
kv = (kv_fp8.view(-1, block_size).float() * kv_scale.view(-1, 1)).to(kv.dtype).view_as(kv)
self.kv_cache[:bsz, start_pos:end_pos] = kv
self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)
if mask is not None: # MHA prefill
q = torch.cat([q_nope, q_pe], dim=-1)
kv = self.wkv_b(kv)
kv = kv.view(bsz, seqlen, self.n_local_heads, self.qk_nope_head_dim + self.v_head_dim)
k_nope, v = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
k = torch.cat([k_nope, k_pe.expand(-1, -1, self.n_local_heads, -1)], dim=-1)
scores = torch.einsum("bshd,bthd->bsht", q, k).mul_(self.softmax_scale)
# indexer
topk_indices = self.indexer(x, qr, start_pos, freqs_cis, mask)
index_mask = torch.full((bsz, seqlen, seqlen), float("-inf"), device=x.device).scatter_(-1, topk_indices, 0)
index_mask += mask
scores += index_mask.unsqueeze(2)
scores = scores.softmax(dim=-1)
x = torch.einsum("bsht,bthd->bshd", scores, v)
else: # MQA decode
if self.dequant_wkv_b is None and self.wkv_b.scale is not None:
self.dequant_wkv_b = weight_dequant(self.wkv_b.weight, self.wkv_b.scale)
wkv_b = self.wkv_b.weight if self.dequant_wkv_b is None else self.dequant_wkv_b
wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank)
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
# indexer
topk_indices = self.indexer(x, qr, start_pos, freqs_cis, mask)
index_mask = torch.full((bsz, 1, end_pos), float("-inf"), device=x.device).scatter_(-1, topk_indices, 0)
scores += index_mask.unsqueeze(2)
scores = scores.softmax(dim=-1)
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
x = self.wo(x.flatten(2))
return x
从python代码上看,首先计算了qk的矩阵乘法得到score,即大小的计算,然后再将选中的token,通过mask的形式加到原来的mask矩阵上,再作用在计算出来的score矩阵上。
显然,从这个代码来看,实际的计算量并没有减少,反而还增加了,因此经过查验发现,真正的DSA执行,其实使用的是FlashMLA中sparse的fwd.cu的kernel。其核心逻辑如下:
// -----------------------------------------------------------
// 核心逻辑来源: kernels/prefill/sparse/fwd.cu
// -----------------------------------------------------------
__global__ void sparse_attn_fwd_kernel(const SparsePrefillParams params, ...) {
// [证据1: 循环次数]
// 这里的 num_topk_blocks 取决于 topk (如 64),而不是 seq_len (如 128k)
// 这证明了计算复杂度被锁定在 O(K) 级别
const int num_topk_blocks = params.topk / B_TOPK;
// CUTLASS 架构通常将 Warpgroup 分为两类:
// 1. Consumer (消费者): 负责计算 (GEMM)
// 2. Producer (生产者): 负责搬运数据 (Memory Copy)
// =======================================================
// Part A: 消费者 Warpgroup (负责计算 Q @ K_sparse)
// =======================================================
if (warpgroup_idx == 0 || warpgroup_idx == 1) {
// 主循环:只循环 num_topk_blocks 次!
// 也就是只算 Indexer 选出来的那几块,绝对不算全量。
for (int block_idx = 0; block_idx < num_topk_blocks; block_idx += 2) {
// 等待 Producer 把稀疏数据搬到 Shared Memory (sK/sV)
// sK_tile 是已经在共享内存里准备好的、紧凑的小块
// 执行矩阵乘法: Accumulator += sQ @ sK_tile
// gemm_ss = Shared-to-Shared GEMM
gemm_ss(..., tiled_mma_QK, sQ_tile, sK_tile, ...);
// ... (Softmax 和 Output 计算) ...
}
}
// =======================================================
// Part B: 生产者 Warpgroup (负责“抓取”数据 Gather)
// =======================================================
else {
// 1. [证据2: 读取�名单]
// 从显存中读取 Indexer 生成的索引表
// gIndices 指向 [Batch, Seq, TopK] 的索引矩阵
int* gIndices = params.indices + s_q_idx*params.topk;
// 辅助 Lambda: 根据块号加载具体的 Token ID
auto load_token_indices = [&](int block_idx) {
for (...) {
// 读取具体的物理 ID (例如:第 9527 号 token)
int t = __ldg(gIndices + offs);
// 计算该 token 在显存中的物理偏移量
token_indices[buf_idx][local_row] = t * params.stride_kv_s_kv;
}
};
// 辅助 Lambda: 稀疏搬运 (Gather Copy)
auto copy_tiles = [&](...) {
for (int local_row = 0; local_row < NUM_ROWS_PER_GROUP; ++local_row) {
// 拿到刚才算出的物理偏移量
int64_t token_index = token_indices[buf_idx][local_row];
for (int tile_idx ...) {
// [证据3: 物理抓取]
// cp_async: 异步拷贝指令
// 源地址 (Src): my_gKV_base + token_index (跳跃式读取!)
// 目的地址 (Dst): my_sKV_base (共享内存中的连续地址)
cp_async_cacheglobal_l2_prefetch_256B(
my_gKV_base + token_index + tile_idx*64, // <--- 关键:跳着读
my_sKV_base + (...) // <--- 关键:存成连续块给 Consumer 用
);
}
}
};
// 生产者主循环
for (int block_idx = 0; block_idx < num_topk_blocks; block_idx += 2) {
load_token_indices(block_idx); // 先查户口:这轮该搬谁?
copy_tiles(...); // 再去搬人:把人从显存抓到 SRAM
// ... (设置 Barrier 通知消费者数据到了) ...
}
}
}
生产者Warpgroup会根据gIndices,也就是通过Lightning Indexer筛选出来的那些token的indice,然后计算其实际的位置,非连续内存,将其放到SRAM的连续内存网格中,并设置Barrier通过消费者数据到了,紧接着消费者Warpgroup就会根据此时放置的位置来获取对应的数据。这里存和取的数据,其实是MLA中的kv latent vector,即在MLA篇章将讲到过的。然后和对应的q在SRAM中做乘法。因此可以看到,实际上QK在kernel实现,并不会做一个完整的矩阵乘,而是一个的计算量。