LORA微调知识记录
1.Lora原理简介
由于 GPU 内存的限制,在训练过程中更新模型权重成本高昂。例如,假设我们有一个 7B 参数的语言模型,用一个权重矩阵 W 表示。在反向传播期间,模型需要学习一个 ΔW 矩阵,旨在更新原始权重,让损失函数值最小。权重更新如下: $$ W_updated = W + ΔW。 $$ 如果权重矩阵 W 包含 7B 个参数,则权重更新矩阵 ΔW 也包含 7B 个参数,计算矩阵 ΔW 非常耗费计算和内存。
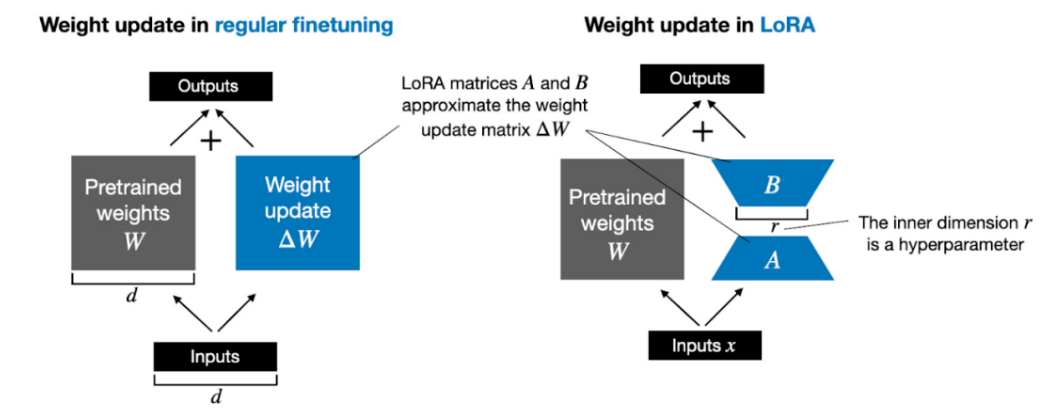
如上所示,ΔW 的分解意味着我们需要用两个较小的 LoRA 矩阵 A 和 B 来表示较大的矩阵 ΔW。如果 A 的行数与 ΔW 相同,B 的列数与 ΔW 相同,我们可以将以上的分解记为 ΔW = AB。(AB 是矩阵 A 和 B 之间的矩阵乘法结果。)秩 r 是一个超参数。例如,如果 ΔW 有 10,000 行和 20,000 列,则需存储 200,000,000 个参数。如果我们选择 r=8 的 A 和 B,则 A 有 10,000 行和 8 列,B 有 8 行和 20,000 列,即 10,000×8 + 8×20,000 = 240,000 个参数,比 200,000,000 个参数少约 830 倍。
2.结论总结:
- 虽然 LLM 训练(或者说在 GPU 上训练出的所有模型)有着不可避免的随机性,但多 lun 训练的结果仍非常一致。
- 如果受 GPU 内存的限制,QLoRA 提供了一种高性价比的折衷方案。它以运行时间增长 39% 的代价,节省了 33% 的内存。
- 在微调 LLM 时,优化器的选择不是影响结果的主要因素。无论是 AdamW、具有调度器 scheduler 的 SGD ,还是具有 scheduler 的 AdamW,对结果的影响都微乎其微。
- 虽然 Adam 经常被认为是需要大量内存的优化器,因为它为每个模型参数引入了两个新参数,但这并不会显著影响 LLM 的峰值内存需求。这是因为大部分内存将被分配用于大型矩阵的乘法,而不是用来保留额外的参数。
- 对于静态数据集,像多轮训练中多次迭代可能效果不佳。这通常会导致过拟和,使训练结果恶化。
- 如果要结合 LoRA,确保它在所有层上应用,而不仅仅是 Key 和 Value 矩阵中,这样才能最大限度地提升模型的性能。
- 调整 LoRA 秩r 和选择合适的 α 值至关重要。提供一个小技巧,试试把 α 值设置成秩 r的两倍。
- 14GB RAM 的单个 GPU 能够在几个小时内高效地微调参数规模达 70 亿的大模型。对于静态数据集,想要让 LLM 强化成「全能选手」,在所有基线任务中都表现优异是不可能完成的。想要解决这个问题需要多样化的数据源,或者使用 LoRA 以外的技术。
- 目前实验的规律表示Lora微调过程中,秩r越大,则越容易过拟合,而秩r越小,则越容易欠拟合。
3.训练过程经验记录
如果数据量较小,则batch_size和acc_step需要设置小一些,acc_step表示几个batch更新一次参数,而batch_size表示一个batch里面有几个数据
微调时一方面要结合特定领域的问答数据,另一方面还要结合日常问答数据,保持模型的自然语言能力